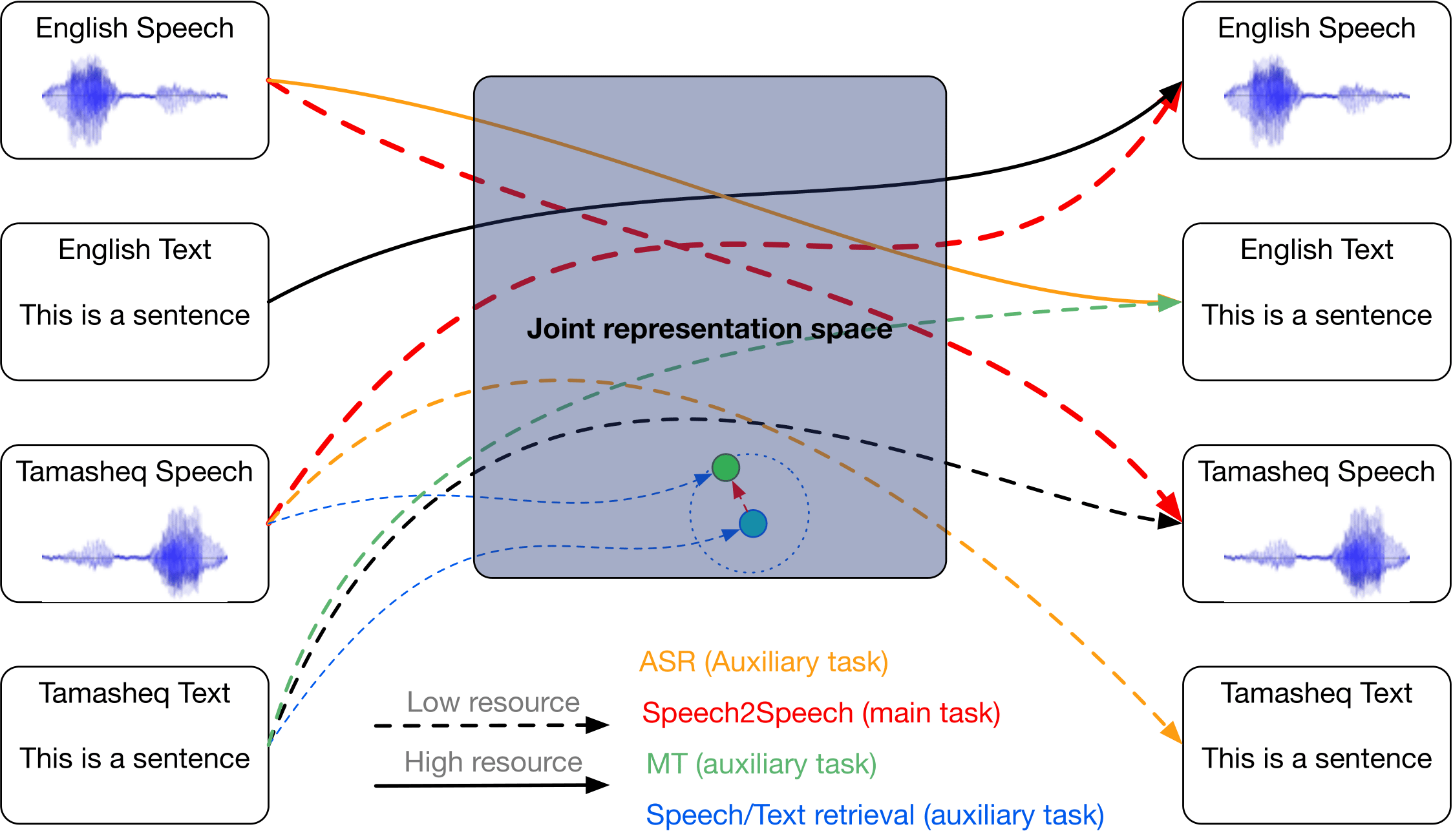
Seamless communication between people speaking different languages is a long term dream of humanity. Artificial intelligence aims at reaching this goal. Despite recent huge improvements made for Machine Translation, Speech Recognition and Speech Translation, Speech to Speech Translation (SST) remains a central problem in natural language processing, especially for under-resourced languages. A solution to this problem is to gather and share information across modalities and large resource languages to create a common multi-modal multi-lingual representation space that could then be used to process under-resourced one through transfer learning, as depicted in Figure 1.
The main goal of our project is twofold
Develop a fully multi modal system for which speech and text can be the input or
output modalities in any considered language that beats the cascade model (i.e. the
system that chain the separate models)
Adapt to under-resourced language
• avoid catastrophic forgetting
• transfer learning with incomplete data (when not all modalities are available)
A fully multi-modal/multilingual system, as depicted in Figure 1, allows to train with multiple objectives (driven by the available data). Tasks such as machine translation (text to text), speech translation (speech to target language text), speech recognition (speech to source language text) and text to speech will be considered as auxiliary tasks to drive the learning of the joint space as well as to ensure a good transfer for the under-resourced languages (where by definition, labeled data in all modalities are not always available).
The following issues will be addressed during the workshop:
• Project speech and text modalities in the same space
Currently, SSL models exist for multi-modal mono-lingual representations in English [Ao et al., 2021] but are difficult to produce in many languages. On the other hand, mono-modal multi-lingual representations exist for speech [Babu et al., 2021] and text modalities [Feng et al., 2020]. The first task of our work will be to merge those two representation spaces into a single multi-model / multi-lingual space.
• Align modalities with different temporalities
An important issue when aligning speech and text sequences is the temporality and granularity of the sequences. More precisely, speech is a long, continuous and redundant audio sequence while the text is shorter and made of discrete tokens. Thus, the following research questions arises: How to design the space? Initial idea consists in combining some language-specific sub-spaces and a shared common space as was done for image translation [Gonzalez-Garcia et al., 2018]. The common space will enable the knowledge transfer across multiple languages, while the language-specific sub-space learns to preserve specificities of each language.
• Transfer knowledge to under-resourced languages
It is common to develop language technologies for under-resourced languages by transferring knowledge from a model pre-trained on a large quantity of data. Exploiting the multi�modal/multi-lingual paradigm, we will investigate the adaptation for low-resourced languages (Fefe/Tamasheq/Pashto) considering different recent methods such as:
– adaptation process (use of adapter networks [Guo et al., 2020], prompting [Brown et al., 2020], transfer learning…)
– semi-supervised adaptation (with incomplete data) [Wotherspoon et al., 2021]
– use of data augmentation techniques
By the end of the Workshop, we will release open-source baseline systems, evaluation, metrics and data for their evaluation.
References
[Ao et al., 2021] Ao, J., Wang, R., Zhou, L., Liu, S., Ren, S., Wu, Y., Ko, T., Li, Q., Zhang, Y., Wei, Z., et al. (2021). Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing. arXiv preprint arXiv:2110.07205.
[Babu et al., 2021] Babu, A., Wang, C., Tjandra, A., Lakhotia, K., Xu, Q., Goyal, N., Singh, K., von Platen, P., Saraf, Y., Pino, J., et al. (2021). Xls-r: Self-supervised cross-lingual speech representation learning at scale. arXiv preprint arXiv:2111.09296.
[Brown et al., 2020] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
[Feng et al., 2020] Feng, F., Yang, Y., Cer, D., Arivazhagan, N., and Wang, W. (2020). Language-agnostic bert sentence embedding. arXiv preprint arXiv:2007.01852.
[Gonzalez-Garcia et al., 2018] Gonzalez-Garcia, A., Van De Weijer, J., and Bengio, Y. (2018). Image-to-image translation for cross-domain disentanglement. NeurIPS.
[Guo et al., 2020] Guo, J., Zhang, Z., Xu, L., Wei, H.-R., Chen, B., and Chen, E. (2020). Incorporating bert into parallel sequence decoding with adapters. Advances in Neural Information Processing Systems.
[Wotherspoon et al., 2021] Wotherspoon, S., Hartmann, W., Snover, M., and Kimball, O. (2021). Improved data selection for domain adaptation in asr. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7018–7022. IEEE.