Multilingual End-to-end ASR for Incomplete Data
Team Leader
Takaaki Hori
Senior Members
Shinji Watanabe
Ramon Astudillo
Martin Karafiat
Graduate Students
Matthew Wiesner
Adi Renduchintala
Murali Karthick Baskar
Jaejin Cho
Senior Affiliates (Part-time Members)
Jan Trmal
Harish Mallidi
Ming Sun
Ryo Aihara
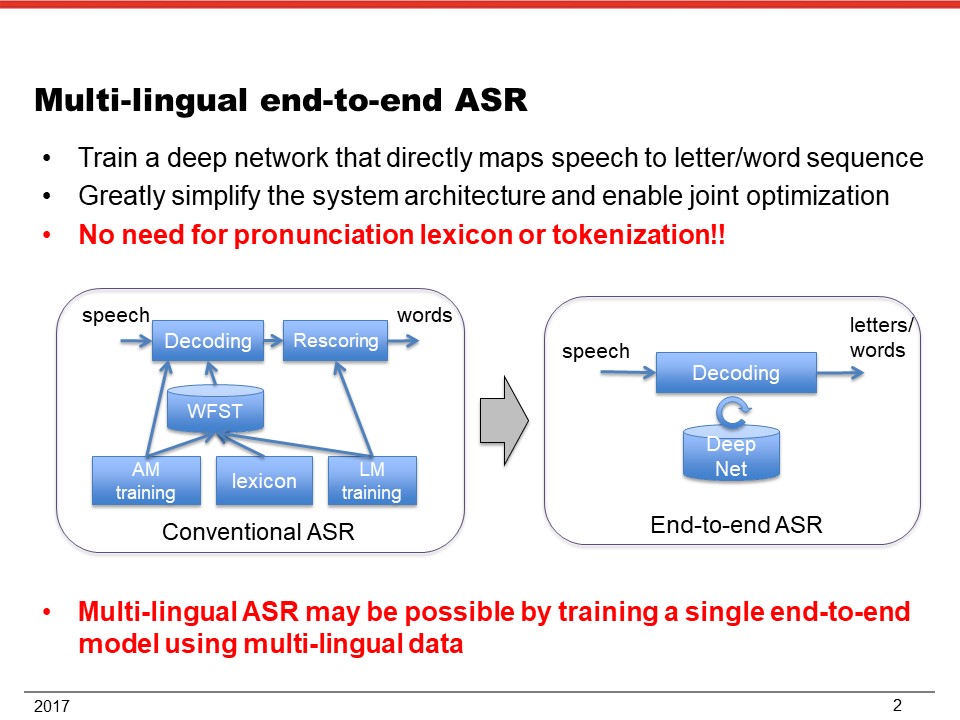
End-to-end automatic speech recognition (ASR) can significantly reduces the burden of developing ASR systems for new languages, by eliminating the need for linguistic information such as pronunciation dictionaries. Nevertheless, some end-to-end ASR systems have recently achieved comparable or better performance than conventional systems in several tasks with the help of novel deep learning techniques. Therefore there is a big potential that we can easily build multilingual speech recognition and understanding systems including minor and low-resource languages without relying on language-specific knowledge. However, the current model training algorithms basically requires paired data, i.e., speech data and the corresponding transcription. Sufficient amount of such complete data is usually unavailable for minor languages, and creating the data set is very expensive and time-consuming. This problem is obviously a bottleneck to rapid deployment of ASR systems to new languages. The goal of this research is to expand the applicability of the end-to-end approach to multilingual speech recognition and understanding for incomplete data, and develop a new technology that makes it possible to build highly accurate systems even for low-resource languages without aligned data.
Abstract
End-to-end automatic speech recognition (ASR) [1,2] can significantly reduce the burden of developing ASR systems for new languages, by eliminating the need for linguistic information such as pronunciation dictionaries. Nevertheless, some end-to-end ASR systems have recently achieved comparable or better performance than conventional systems in several tasks [3-7], even though they were trained with a completely data-driven method without linguistic knowledge. Therefore, there is a big potential that we can easily build multilingual speech recognition and understanding systems including minor and lowresource languages without relying on language-specific knowledge. However, the current model training algorithms basically requires paired data, i.e., speech data and the corresponding transcription. Sufficient amount of such complete data is usually unavailable for minor languages, and creating the data set is very expensive and time consuming. This problem is obviously a bottleneck to rapid deployment of ASR systems to new languages. The goal of this research is to expand the applicability of the end-to-end approach to multilingual speech recognition and understanding for incomplete data, and develop a new technology that makes it possible to build highly accurate systems even for low-resource languages without aligned data. The research team includes outstanding researchers who have intensively worked on recent successful end-to-end systems for speech recognition and spoken keyword search. Accordingly, the team will successfully accomplish this task and yield plenty of outcomes for this exciting and challenging goals.
Techniques
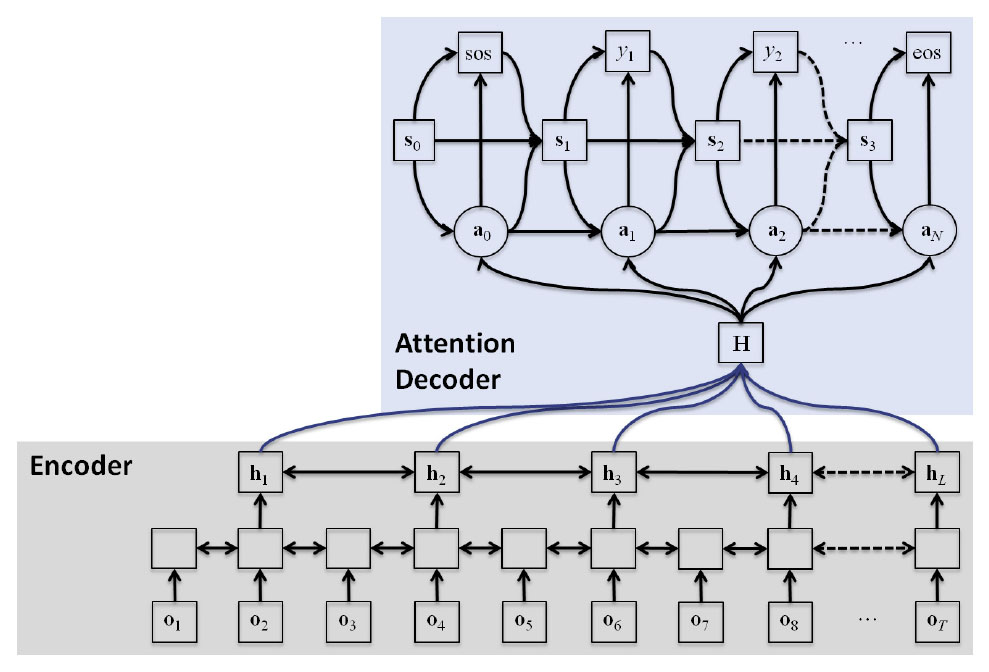
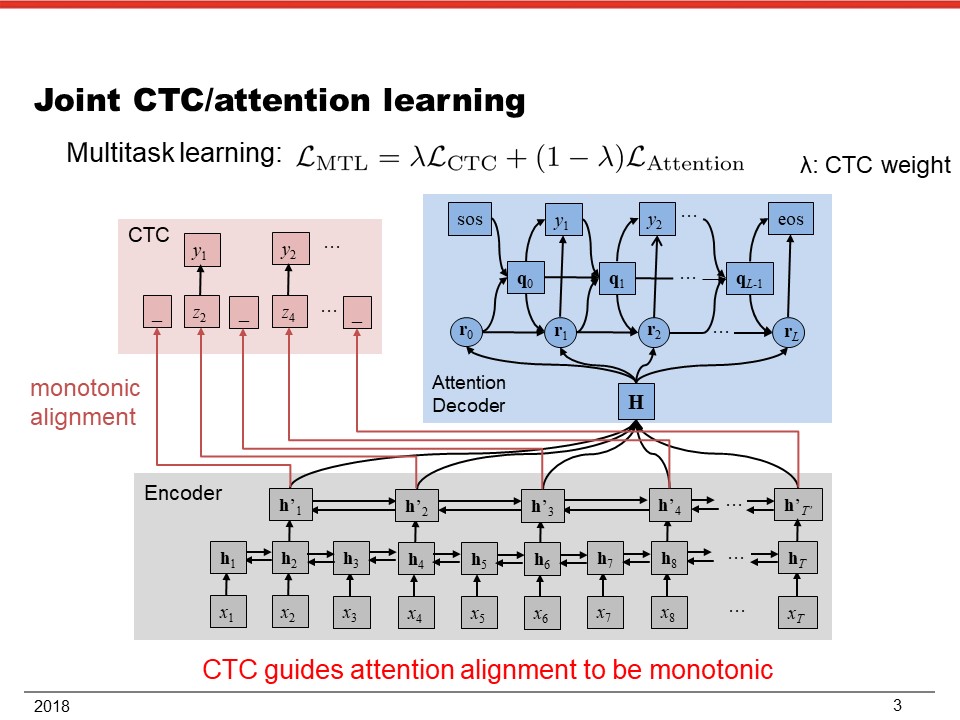
I. End-to-end speech recognition methods, for example (1) connectionist temporal classification (CTC) [1], (2) attention-based encoder decoder [2], (3) listen, attend and spell (LAS) method [3], (4) joint CTC/attention learning and decoding [4,5], (5) segment-based end-to-end model [6], (6) and deep CNN/BLSTM architecture [7]. These methods have already achieved almost comparable to or better performance than conventional methods in English, Chinese, and Japanese tasks. They may be combined loosely by joint decoding or tightly integrated into a single end-to-end network to further improve the performance.
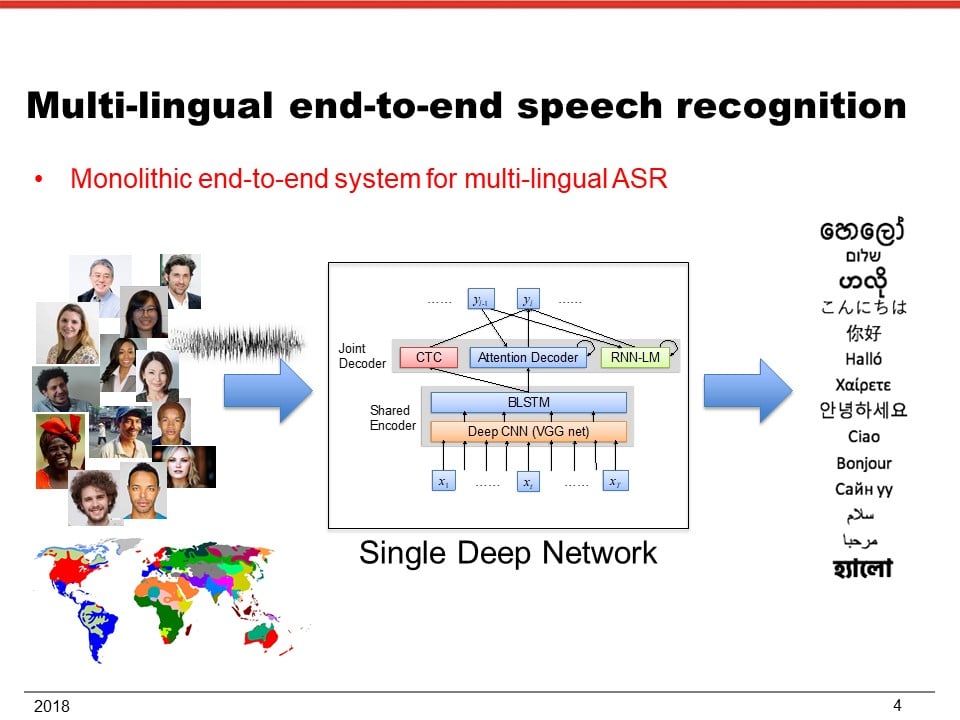
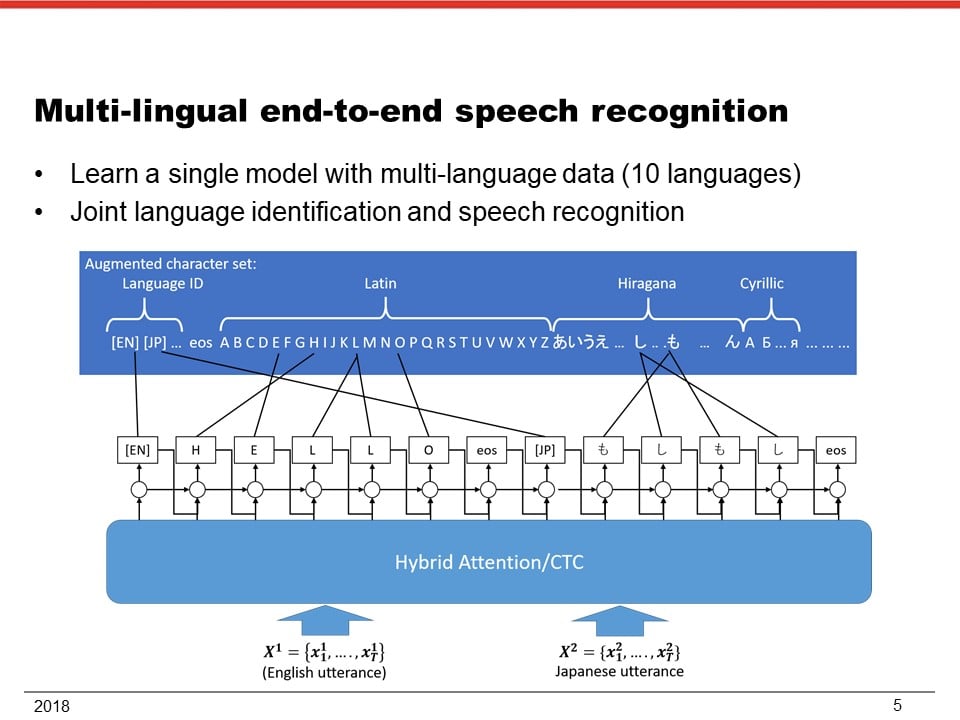
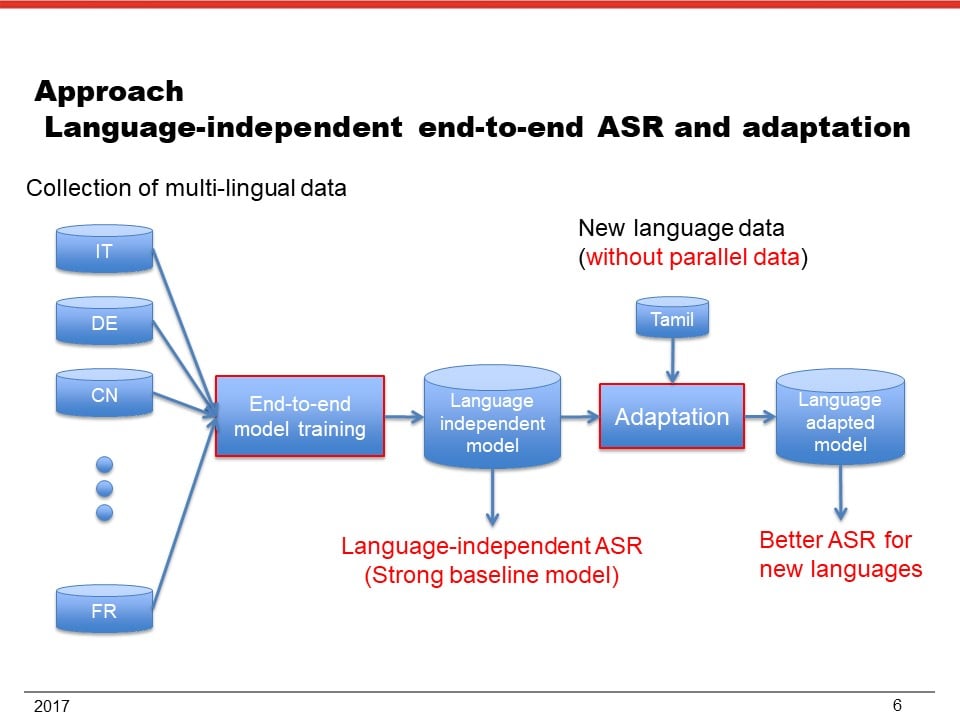
II. Language-independent architecture: recently, it has been demonstrated that a single end-to-end model can be used to recognize multilingual speech by just training it with multiple speech corpora from different languages [8]. This language-independent model has outperformed the language-dependent models in most languages. This result implies that the model could also improve the accuracy for low resource languages and further boost it by language adaptation.
III. Low-resource keyword search: end-to-end spoken keyword search method can find keywords from speech using an acoustic auto-encoder and query embedding [9]. This architecture could be used to acquire language-independent semantic representation of speech, which potentially improves ASR performance and could be useful for speech understanding tasks.
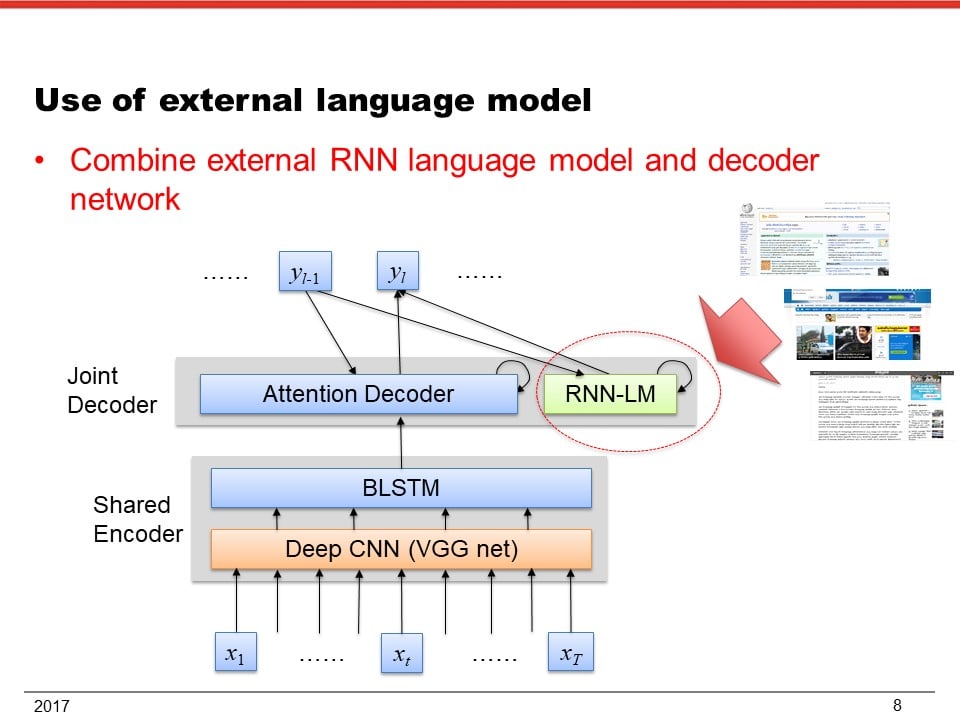
IV. Training algorithms for incomplete data: key issues of this research are how to use unpaired speech and text data and how to acquire unknown acoustic-linguistic mapping for speech recognition. One approach could be the use of external language models trained only from text. The end-to-end model in [5] has an architecture that integrates a recurrent neural network language model (RNNLM) with the encoder-decoder network, where the RNNLM can be trained with external text data without speech. This approach can boost the ASR performance using only text data. Another approach could be the use of deep learning techniques for non-aligned data. Recently, a ranking loss function has been used to obtain both aligned and discriminative representations [10]. Cycle-consistent adversarial networks have been proposed for image-to-image translation problems using unpaired data [11]. Our research will expand these kinds of techniques to sequence-to-sequence models for end-to-end ASR.
Software platform and task design
Platform: we will assemble a publicly available state-of-the-art end-to-end ASR baseline using a popular deep learning framework such as chainer, pytouch, and tensorflow for training and decoding, and extend the architecture and learning algorithms for multilingual end-to-end ASR with incomplete data.
Task design: novel techniques will be evaluated with multilingual speech corpora such as TED, VoxForge, CallHome, and Babel. Starting with a baseline multi-lingual end-to-end ASR model trained with diversified multi-lingual data, we will evaluate novel training/adaptation techniques for incomplete data, where we simulate incomplete data situations in minor languages, e.g., Tamil and Egyptian Arabic. We will also tackle with different recording environment and speaking style from training data using noise robust techniques. Evaluation metrics will be token error rate and keyword accuracy (e.g. based on the Babel setup).
References
[1] A. Graves and J. Navdeep, “Towards end-to-end speech recognition with recurrent neural networks,” Proc. ICML 2014 (2014)
[2] J. Chorowski, et al. “Attention-Based Models for Speech Recognition.” Proc. NIPS, pp. 577–585 (2015)
[3] W. Chan, N. Jaitly, Q. V. Le, and O. Vinyals, “Listen, attend and spell,” Proc. ICASSP, pp. 4960–4964 (2016)
[4] S. Kim, T. Hori, and S. Watanabe, “Joint CTC-attention based end-to-end speech recognition using multi-task learning,” Proc. ICASSP, pp. 4835–4839 (2017)
[5] T. Hori, S. Watanabe, Y. Zhang and W. Chan, “Advances in Joint CTC-Attention based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM,” Proc. Interspeech (2017)
[6] Y. Zhang, W. Chan and N. Jaitly, “Very deep convolutional networks for end-to-end speech recognition,” Proc. ICASSP, pp. 4845–4849 (2017)
[7] L. Lu, L. Kong, C. Dyer, and N. A. Smith, “Multi-task learning with CTC and segmental CRF for speech recognition,” Proc. Interspeech (2017)
[8] S. Watanabe, T. Hori, and J. Hershey, “Language independent end-to-end architecture for joint language identification and speech recognition,” to appear in ASRU 2017
[9] K. Audhkhasi, A. Rosenberg, A. Sethy, B. Ramabhadran and B. Kingsbury, “End-to-End ASR-free Keyword Search from Speech,” in IEEE Journal of Selected Topics in Signal Processing (2017)
[10] Y. Aytar, C. Vondrick, A. Torralba, “See, Hear, and Read: Deep Aligned Representations,” arXiv preprint arXiv:1706.00932 (2017).
[11] J. Zhu, T. Park, P. Isola, A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” arXiv preprint arXiv:1703.10593 (2017).


Upcoming Seminars
There are no upcoming events.