Grounded Sequence to Sequence Transduction
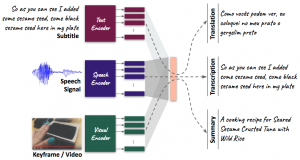
Video understanding is one of the hardest challenges in Artificial Intelligence research. If a machine can look at videos, and “understand” the events that are being shown, then machines could learn by themselves, perhaps even without supervision, simply by “watching” broadcast TV, Facebook, Youtube, or similar sites.
Making progress towards this goal will require contributions from experts in diverse fields, including computer vision, automatic speech recognition, machine translation, natural language processing, multi-modal information processing, and multi-media. This makes such research a prime candidate for work during a JSALT workshop. Our proposed team will develop methods that exploit multimodality to process and analyze videos to accomplish three main tasks: speech captioning, video-to-text summarization and translation into a different language. These tasks are diverse but not unrelated. Therefore, we propose to model them using a multi-task learning framework where these (and other, auxiliary) tasks can benefit from shared representations.
The tasks we propose generate natural language, which has a number of well-known challenges, such as dealing with lexical, syntactic and semantic ambiguities, and referential resolution. Grounding language using other modalities, e.g. visual and audio information such as what we propose here, can help overcome these challenges. Information extracted from speech, audio and video will serve as rich context models for the various tasks we plan to address.
While we believe that our team has all the required skills to successfully tackle the proposed work, we would like to point out that our tasks offer synergies to the other proposed JSALT teams on “inspecting neural machine translation” and “learning semantic sequence representations” – and we plan to fully embrace that opportunity.
- Multitask learning
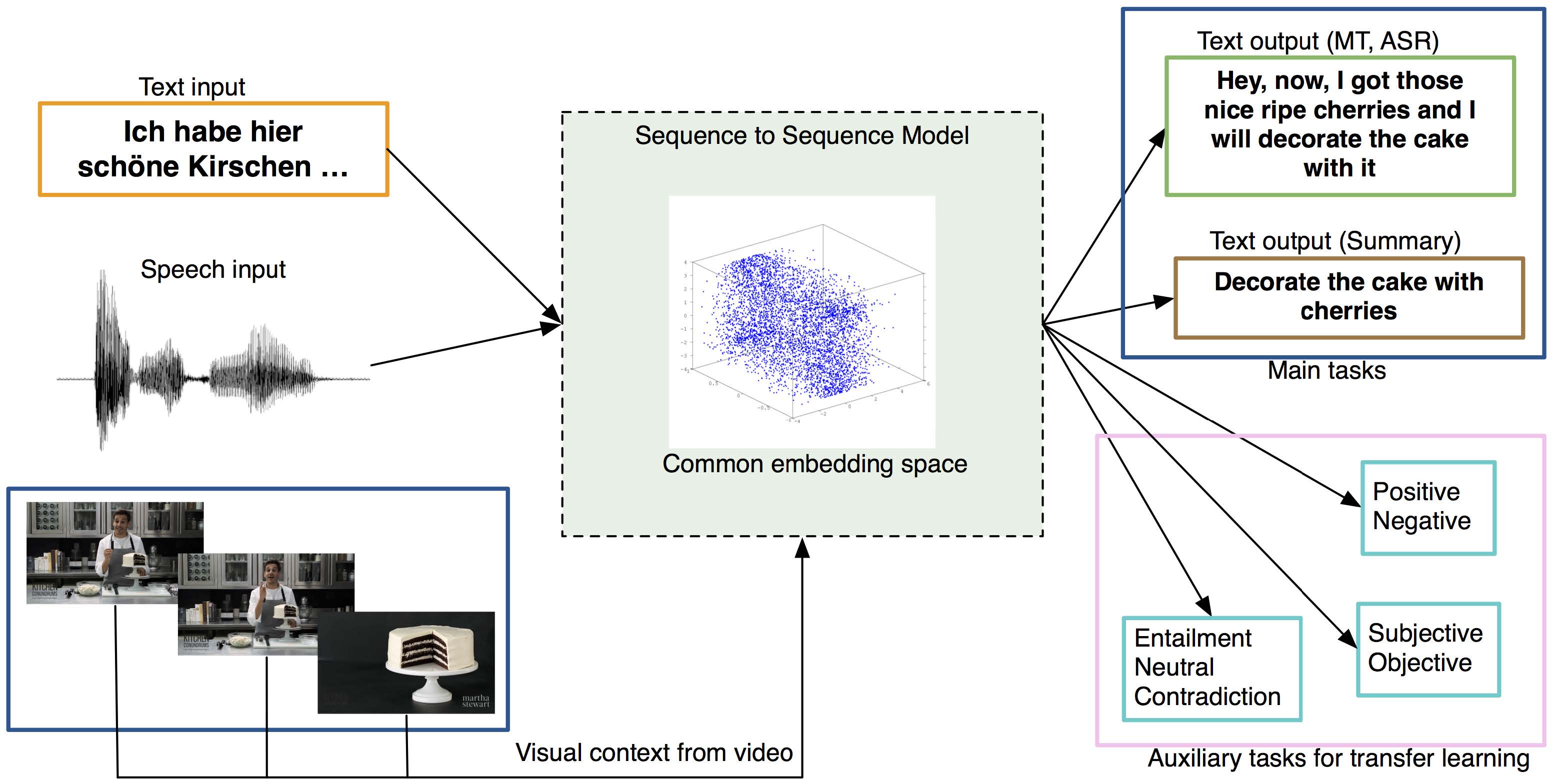
Multitask learning (MTL) can improve models by requiring it to be useful for more than one task [3], e.g. by improving sentence compression using eye-gaze data [7], or by sharing an attention mechanism across different translation languages [6]. In the context of the multimodal tasks proposed in this project, MTL has the potential to make a substantial impact because we can learn better models without requiring paired annotations over multiple languages and modalities. This is important because it is very expensive to collect fully-aligned multilingual multimodal data. [4] shows that transfer learning increases performance on text-based classification tasks when learned with unsupervised data, and [5] shows that multimodal translation can benefit from MTL by learning to translate and to predict visual representations. We propose to combine our main tasks (speech captioning, video-to-text summarization and translation) along with a number of auxiliary tasks (e.g. text-only machine translation/summarization, visual question answering, topic classification) in a single learning framework, as shown in Figure 1.
Figure 1: High-level overview of the proposed work. The aim of MTL is to learn a single shared space for multiple
modalities across multiple domains, which will improve performance for the main and auxiliary tasks.
In MTL with multiple modalities, the inputs of different modalities need to be processed by different types of encoders, such as bi-directional RNNs for text and deep CNNs for images. Recent research shows that representing input in a fixed size vector does not provide the best results for certain tasks, like translation. Therefore, when dealing with multiple modalities, designing the shared space remains an open issue. This shared space should be able to represent several semantically-related inputs into the same representation such that the decoder can operate seamlessly when fed with inputs from various modalities or languages.
- Tasks
Multimodality has been explored to some extent for the tasks of text translation using static images, and speech recognition using isolated utterances. In this project, following a multitask learning framework, we will address
Figure 1: High-level overview of the proposed work. The aim of MTL is to learn a single shared space for multiple modalities across multiple domains, which will improve performance for the main and auxiliary tasks, audio-visual captioning, summarization and translation as main tasks, and use other well established tasks as auxiliary tasks, such as text-only translation, language modeling, story segmentation, and classification (topic, entailment, semantic similarity, etc.).
For captioning, we will investigate ways to improve transcription of videos by adding visual information. We have previously studied ways in which sequence models (as well as other end-to-end speech recognition models) can be adapted to pseudo-static context. We will further investigate how to best condition the output of a speech-totext system on static context, and how to extend our approach to dynamic and supra-segmental context. We will also investigate how multitask training and multimodality can help the recognition by exploring visual cues: can we improve the language part of our sequence model (not necessarily a traditional “language model”) by seeing “it”, and knowing what can be done with it? Can we better adapt to the acoustics by including scene or action information? Our initial results indicate that the answer is “yes”, but we intend to perform more detailed analysis on these questions on a large corpus of videos.
For summarization, we aim to create a shared symbolic “explanation” for multiple parallel videos of the same event, which can be used to align and situate the individual files with respect to each other. In other words, taking multiple videos of a high-profile public events such as the “San Diego Fireworks Fail”, we want to explain what happened when (in what order) and then align these explanations with observables in the individual videos that have been created (with different view-points and different temporal offsets) of the same event. Candidate datasets are high-profile events of which multiple social media uploads exist, such as high-profile sport events, structured repetitive videos (cooking instructions), or public safety videos. The goal could be to flag and explain outliers, or otherwise leverage the information contained in a deep shared representation. A variant of this work will investigate how a short textual summary of a cluster of videos (rather than a single video) will improve video retrieval.
For translation, we will advance research on the recent field of multimodal machine translation by departing from static images to incorporate audio-visual information from videos (with not only speech but other paralinguistic signals from the audio). Current work exploits general visual representations extracted from a single entire image, disregarding the fact that the text to be translated may refer to specific parts of the image and not explicitly modeling any mappings between vision and language, e.g. words and objects. While attention mechanisms attempt to do so, this is done at low level, which we believe is not effective in capturing conceptual mappings. Some images contain much more information than the text to translate (and v.v.), which makes attending to important relationships between visual and linguistic signals difficult. By exploring videos we aim not only to inform the model with the additional modalities, but also take advantage of the dynamic and sequential nature of this information for better alignment between the textual and audio-visual cues. For example, the video will often have frames, where the object referred to in the text, becomes more salient through zooming in.
Evaluation Each of these tasks can be evaluated objectively using quantitative methods and metrics that measure performance based on system output (machine translation: BLEU, METEOR, etc.; speech-to-text: WER, PPL, token error rate, etc.; summarization: ROUGE or P@N, Pr/Re if framed as a retrieval task, etc.). In addition, we can evaluate the representations for each of them in external tasks, e.g. using classification as auxiliary diagnostic metric or in a retrieval task: given a text query (utterance), the model has to retrieve the other utterances of the same video. Finally, we can study the contribution of one given task to the performance of other tasks in the MTL framework.
- Datasets
As main dataset, we will use the “How-to” dataset of instructional videos harvested from the web by CMU [8]. It has 480 hours of videos with subtitles, a total of 273k sentences/ 5.6M words, of which:
- 90 hours of subtitles can be aligned quite verbatim with the audio (so we treat them as transcripts): 55K
utterances, 20K vocabulary size, 1.1M words - 390 hours exhibit less verbatim alignments, but can be used for summarization or training experiments Each
utterance has on average 18 words for 8-10 seconds of audio.
Before the workshop, this dataset will be expanded with translations and summaries. Our current plan is to activate the expertise of Prof. Jeff Bigham [2] at CMU, a past collaborator of co-lead Metze, in crowd-sourcing the annotation of audio and audio-visual data. In collaboration with our co-lead Fügen at Facebook’s AML team, we are also investigating the possibility of expanding existing datasets, establishing a new dataset, or working on multiple corpora.
We will also explore a number of already existing additional datasets for the auxiliary tasks, such as the Multi30K dataset for multimodal machine translation with static images, the VQA dataset, and WMT news translation text for text-only translation.
- Plan
4.1 Before workshop
- Expand existing “How-to” dataset with summaries and translations, establish other data sources.
- Establish best practices by comparing and exchanging components of the project leaders’ existing speech recognition and machine translation approaches.
- Build baselines for each task independently, based on various well established architectures and representations.
4.2 During workshop
- Devise basic framework for each main task: decide on architecture(s), design of the encoders and decoders, feature extraction (CNN, etc), and level of representations: words, BPE, characters.
- Devise the common (embedding) space using MTL: which multiple modalities will be shared and how (audio, video, both), which auxiliary tasks will be used, etc.
- Extract visual information from video: object features, place features and action features.
- Exploit different types of regularization during training to encourage similar representations for realizations of a same concept in different modalities.
- Study how to exploit sequential nature of videos to extract the “story” behind it.
- Investigate ways to align and arrange the videos using high-level descriptors.
4.3 Long-term plans
While we believe that we can make significant progress on the proposed topic, it is clear that we will not be able to solve “video understanding”.In preparation of this proposal, the project leaders spoke to a number of other colleagues, who expressed interest in potentially leading future workshops in the general “video understanding” area, and we will support these attempts. Multimodal machine translation has already established community-supported evaluation [1], and we intend to capitalize on this experience and create interest in our tasks in other communities, such as MediaEval and/ or Trecvid.
- Expected outcomes
This project covers the definition of new tasks that can model and measure how well algorithms understand videos. It is a highly interdisciplinary project, requiring expertise from machine learning (in particular representation learning), natural language processing (machine translation and summarization), speech and audio processing and computer vision. By the end of the workshop we expect to have the following main outcomes:
- Progress towards the new task of video understanding through the various subtasks proposed.
- Implementations and working models that – given a set of videos – can perform speech transcription, summarization and translation and, as a by-product, better approaches to explicitly align audio, visual and textual content.
- Novel multitask models to perform transfer learning on generative tasks rather than classification tasks.
- Performance benchmarks on these models, which will be evaluated in different ways: we will measure performance of their final output independently, using standard metrics for each of this task; we will study the synergies across tasks and how much each task benefits from others in the multi-task learning framework; and finally, we will analyze the representations that are learned and their use in other tasks, such as classification.
- Large-scale datasets to enable further research on all of the subtasks proposed as well as on other aspects of video understanding.
References
1] Multimodal machine translation. http://www.statmt.org/wmt16/multimodal-task.html.
[2] Jeff Bigham. https://www.cs.cmu.edu/˜jbigham/.
[3] Rich Caruana. Multitask learning. Machine Learning, 28:41–75, 1997.
[4] A. Conneau, D. Kiela, H. Schwenk, L. Barrault, and A. Bordes. Supervised learning of universal sentence representations
from natural language inference data. In EMNLP, 2017.
[5] D. Elliott and Á. Kádár. Imagination improves multimodal translation. In IJCNLP, 2017.
[6] O. Firat, K. Cho, and Y. Bengio. Multi-way, multilingual neural machine translation with a shared attention mechanism.
In NAACL, 2016.
[7] Sigrid Klerke, Yoav Goldberg, and Anders Søgaard. Improving sentence compression by learning to predict gaze. In
NAACL, 2016.
[8] Yajie Miao, Lu Jiang, Hao Zhang, and Florian Metze. Improvements to speaker adaptive training of deep neural networks.
In IEEE Workshop on Spoken Language Technology, South Lake Tahoe, 2014.