General-Purpose Sentence Representation Learning
Sam Bowman
Senior Members
Ellie Pavlick
Ian Tenney
Edouard Grave
Graduate Students
Alex Wang
Roma Patel
Rachel Rudinger
Raghavendra Pappagari
Tom McCoy
Najoung Kim
Undergraduate Students
Shuning Jin
Berlin Chen
Alexis Ross
Senior Affiliates (Part-time Members)
Benjamin Van Durme
Tal Linzen
Katherin Yu
Ves Stoyanov
Dipanjan Das
The General-Purpose Sentence Representation Learning team will work to train deep learning models to understand sentence meaning. Candidate systems will be evaluated on their ability to solve a suite of ten language understanding tasks using a single shared sentence encoder component, combined with a set of ten lightweight task-specific attention models. We expect to explore new methods for unsupervised learning, new methods for multitasking and transfer learning, and new methods for linguistically sophisticated error analysis. Join us!
The Problem
General purpose distributional word representations produced using unsupervised learning methods like word2vec (Mikolov et al. ‘13) have yielded substantial performance gains over task-specific representations in neural network models for nearly every language understanding task in which they’ve been studied. Similarly, general purpose image representations from neural network models trained on ImageNet (Deng et al. ‘09) have proven widely effective across a range of computer vision tasks. However, no comparably useful technology exists at the sentence level.
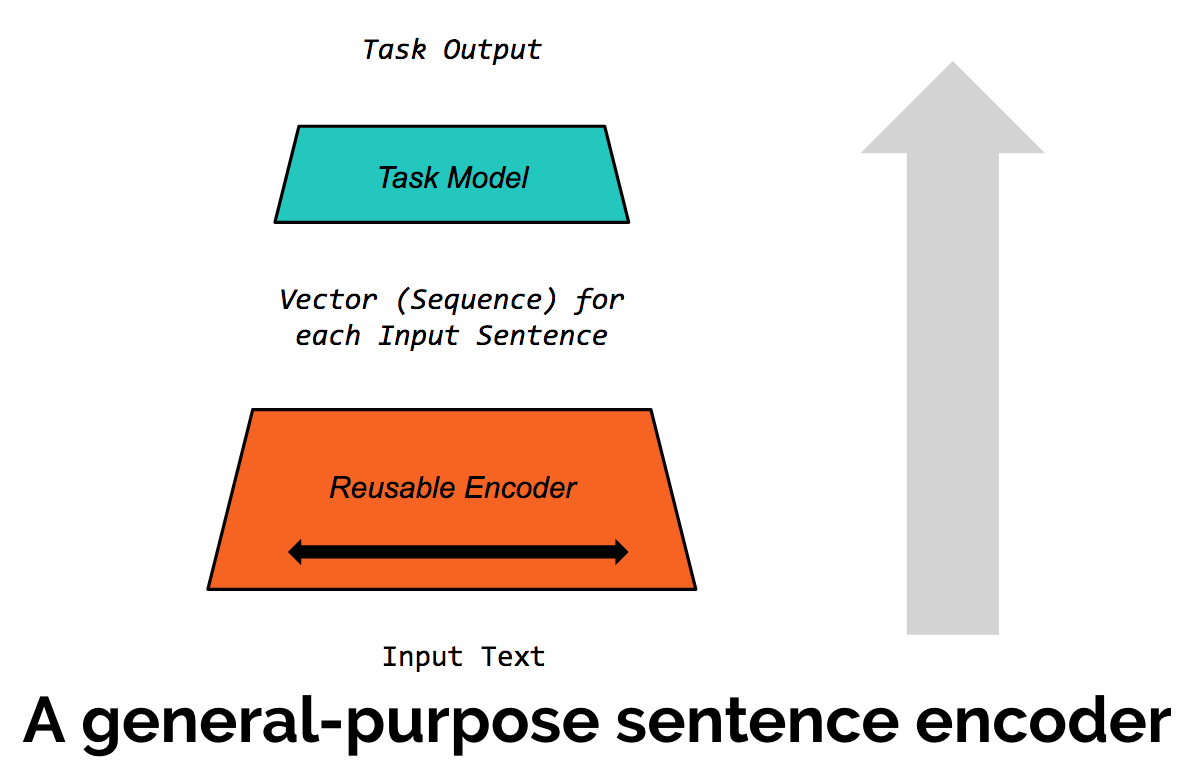
A nascent line of work in this area aims to use unsupervised learning methods on abundant unannotated text (e.g., Kiros et al. ‘15, Hill et al. ‘16, Peters et al. ‘17) or supervised learning methods on data-rich tasks like translation (e.g., Conneau et al. ‘17, McCann et al. ‘17) to train compositional encoder models that can extract general-purpose distributed representations for sentences. These representations are meant to capture the meanings of sentences, their connotations, and their literal lexical contents, and are meant to serve in part as a continuous analogue to the logical forms used in mainstream linguistic theory.
Were these general-purpose encoders to be effective, they would supplement or replace task-specific sentence understanding components, and thereby dramatically reduce the amount of annotated data needed to build effective systems for either new or existing language understanding tasks.
However, these methods are still far from mature. The standard benchmarks for this task do not resemble realistic use cases, and generally assume that downstream task models are built using logistic regression, rather than the complex neural network architectures that are in fact widely employed for language understanding tasks. There have also been no large-scale demonstrations that methods like these produce gains over the state of the art on established tasks, and the representations that they extract do not appear to fully capture either the words and structures they contain or their high-level semantic properties. We believe that expanding on work in this area with thorough, realistic evaluations and larger-scale experiments offers an opportunity to realize large empirical gains.
Proposal
Before the start of the workshop, we propose to develop a benchmark suite for the evaluation of general purpose sentence representation learning models that will make it possible, for the first time, to compare such models on their ability to produce gains in realistic settings. Our benchmark will be built to measure system performance in settings that are closely analogous to likely application areas for this technology, such as the deployment of an intent detection system for an Alexa skill where labeled data is scarce, or the deployment of a machine translation system where data is abundant but performance is still inadequate.
In particular, we expect this benchmark suite to break from prior work in two ways: It will support the evaluations of models which use attention (Bahdanau et al. ‘14) or other methods that require a sentence to be represented in a form more structured than a single vector, and it will support evaluations on data-rich downstream tasks for which it is not appropriate to use a simple linear regression model to predict task labels from sentence representations.
During the workshop itself, we plan to use all of the methods at our disposal to build systems which perform well on these benchmarks, giving roughly equal weight to the development of training methods that exploit unlabeled data, the development of training methods that exploit existing abundant labeled data, and analytic work on the evaluation and analysis of existing methods in support of our engineering research.
The workshop will produce trained models and open-source software packages as its chief output. The workshop will have succeeded either if these models outperform the state of the art in a significant number of the tasks targeted in our benchmark, or if these models match the state of the art on a significant number of these tasks, but do so using only a small fraction of the available training data.
Plan of Work
During the 2017–18 academic year, a benchmarks and baselines team consisting of Alex Wang (NYU), Sam Bowman (NYU), Omer Levy (UW), and Felix Hill (DeepMind) will develop a public online benchmark platform that automatically evaluates systems for sentence representation. Building on Conneau et al.’s SentEval, this platform will evaluate models on a representative set of 8–10 downstream sentence or sentence-pair understanding tasks1 which vary widely in the aspects of meaning they cover and in their amounts of available training data. This team will also develop and tune a baseline system based on bidirectional LSTMs with attention (or any similar technology that might represent the state of the art at the time of completion), trained using multitask learning over the training data for the selected tasks.
Research on-site at JHU will aim to build models and training methods that will allow us to perform well on these benchmarks. We plan to form small research teams on three topics:
An unsupervised learning team will focus on evaluating and extending state-of-the-art methods for learning from raw text data, and will focus both on the shared benchmark and, secondarily, on similar non-English benchmarks. Viable directions for research include latent variable models, generative adversarial network-inspired models trained to distinguish real text from language model samples, and methods for extracting pseudo-labels from naturally occurring sources.
A transfer and multitask learning team will focus on two related issues. Work on methods will focus on ensuring that models that are trained jointly on multiple tasks meaningfully share representations and yield improvements over single-task models. Work on task selection for pretraining will explore supervised learning tasks with large datasets, grounded reinforcement learning environments, and purpose-built semantic scaffolding tasks (inspired by syntactic scaffolding; Swayamdipta et al. ‘17) that encourage the learning of representations with desired properties. Likely candidate tasks include translation language pairs with large datasets (such as English–French or English–Chinese), SNLI/MultiNLI, Quora duplicate questions, and Paralex. Task selection will involve a good deal of structured trial and error, and could be a good fit for an undergraduate participant.
An analysis and evaluation team will focus on understanding the behaviors of the systems developed by other two teams and providing actionable feedback. This team will focus on developing qualitative and quantitative experiments (following Adi et al. ‘17, Ettinger et al. ‘17, Isabelle et al. ‘17, or Jia and Liang ‘17) that identify undesirable properties of learned representations, and investigate interventions to address these properties. Members of this team will also ensure that a standardized evaluation on the benchmark, and on any newly added evaluation experiments, is conducted regularly.