Remote Monitoring of Neurodegeneration through Speech
- Research Group of the 2016 Third Frederick Jelinek Memorial Summer Workshop
- Team Presentations and Publications

Introduction
Alzheimer’s disease (AD) is the most common neurodegenerative disorder. It generally deteriorates memory function, then language, then executive function to the point where simple activities of daily living (ADLs) become difficult (e.g. taking medicine or turning off a stove). Parkinson’s disease (PD) is the second most common neurodegenerative disease, also primarily affecting individuals of advanced age. Its cardinal symptoms include akinesia, tremor, rigidity, and postural imbalance. Together, AD and PD afflict approximately 55 million people, and there is no cure. Currently, professional or informal caregivers look after these individuals, either at home or in long-term care facilities. Caregiving is already a great, expensive burden on the system, but things will soon become far worse. Populations of many nations are aging rapidly and, with over 12% of people above the age of 65 having either AD or PD, incidence rates are set to triple over the next few decades.
Monitoring and assessment are vital, but current models are unsustainable. Patients need to be monitored regularly (e.g. to check if medication needs to be updated), which is expensive, time-consuming, and especially difficult when travelling to the closest neurologist is unrealistic. Monitoring patients using non-intrusive sensors to collect data during ADLs from speech, gait, and handwriting, can help to reduce the burden.
Our goal is to design and evaluate a system for monitoring neurodegenerative disorders over the phone, as illustrated in Figure 1. The doctor or an automatic system can contact the patient either on a regular basis or upon detecting a significant change in the patient’s behavior. During this interaction, the doctor or the automatic system has access to all the sensor-based evaluations of the patient’s ADLs and his/her biometric data (already stored on the server). The doctor/system can remind these individuals to take their medicine, can initiate dedicated speech-based tests, and can recommend medication changes or face-to-face meetings in the clinic.

Figure 1: Monitoring system
The analysis is based on the fact that these disorders cause characteristic lexical, syntactic, and spectro-temporal acoustic deviations from non-pathological speech, and in a similar way, deviations from non-pathologic gait and handwriting. We will learn temporal models combining non-intrusive sensor data-based tests to allow a monitoring system to initiate intervention by the medical expert or automatic analysis system.
Background
We have uncovered specific differences between pathological speech and normative control speech using existing feature extraction code (in Matlab and Python), which will be provided to the workshop by team members, to extract over 400 acoustic (e.g. pitch variation, phonation rate, wavelet, spectral and cepstral analyses, harmonicity, stability, and periodicity (e.g. jitter, shimmer, correlation dimension, and recurrence period density entropy)), lexico-syntactic (e.g. noun-to-pronoun ration, Yngve depth), semantic (e.g. word precision), phonetic (e.g. speaking rate and pitch dynamics) [Trevino et al, 2011), phonological [Cernak et al., 2016], conversation-based, and articulatory [Yu et al, 2014-15] features from audio and associated transcripts.
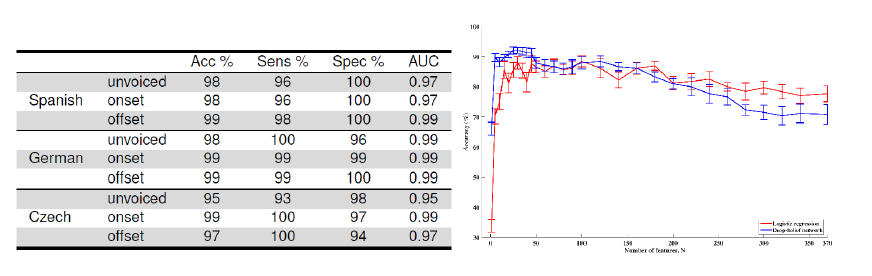
Figure 2: Accuracy, sensitivity, specificity, and AUC for identification of PD from controls across three languages (left, Orozco 2015), and accuracy of identification of AD from controls using logistic regression and deep-belief networks (right, Fraser et al. 2016).
Our team has obtained very high accuracy in binary classification between pathological and non-pathological speech, as shown in Figure 2. Analysis has also shown the heterogeneity of pathological speech. For example, our recent work has shown that speakers with AD can be individually clustered according to either differences in fluency or in semantics [Fraser et al., 2016]. Our team has also, using phoneme-dependent and articulatory coordination-based features, with audio from elderly subjects over a 4 year period, achieved an average equal error rate (EER) of about 13.5% in detection of mild cognitive impairment [Yu et al, 2015]. This same speech feature methodology has been used with promise in detecting PD [Williamson et al, 2015]. In addition, we are working on discriminating between people with dementia and people with other functional memory disorders using computer-aided conversational analysis. Having automatic, home-based screening for such cases would enable clinicians to profile and track changes in speech and language over time, and hence give a more nuanced picture compared to the ‘snapshot’ obtained when patients go for a checkup. Given this strong starting point, we intend to train new models to answer deeper questions of discriminability, as detailed below.
Platform, tools, and data
 Phil Green is leading the CloudCAST initiative, which is an international effort to develop and distribute speech technology “in the cloud” for clinicians and therapists worldwide. CloudCAST includes new data collection and merging of UA-Speech and TORGO databases of dysarthric speech, from UIUC and Toronto, respectively. CloudCAST will also help to disseminate the results of the workshop to enrolled clinicians directly. We will also use the publicly-available DementiaBank database of individuals with (N=198) and without (N=200) Alzheimer’s disease describing pictures verbally, as well as language assessment tasks being collected online from normative speakers (currently, N>80) and speakers with dementia (currently, N=30) from Toronto (Talk2Me). Talk2Me uses the same MySQL schema as CloudCAST and is being supported by the AGE-WELL National Centres of Excellence, the Alzheimer’s Society, and the Scarborough Centre for Healthy Communities, including with ongoing data collection. Importantly, none of these data will require HIPAA training or ethics board approval. From Antioquia, we currently have two databases, (1) PC-GITA [Orozco 2015] which contains recordings of 100 speakers, 50 with PD and 50 age- and gender-matched healthy controls, and (2) ongoing data collection with recordings of speech, gait, and handwriting of currently 30 patients with PD.
Phil Green is leading the CloudCAST initiative, which is an international effort to develop and distribute speech technology “in the cloud” for clinicians and therapists worldwide. CloudCAST includes new data collection and merging of UA-Speech and TORGO databases of dysarthric speech, from UIUC and Toronto, respectively. CloudCAST will also help to disseminate the results of the workshop to enrolled clinicians directly. We will also use the publicly-available DementiaBank database of individuals with (N=198) and without (N=200) Alzheimer’s disease describing pictures verbally, as well as language assessment tasks being collected online from normative speakers (currently, N>80) and speakers with dementia (currently, N=30) from Toronto (Talk2Me). Talk2Me uses the same MySQL schema as CloudCAST and is being supported by the AGE-WELL National Centres of Excellence, the Alzheimer’s Society, and the Scarborough Centre for Healthy Communities, including with ongoing data collection. Importantly, none of these data will require HIPAA training or ethics board approval. From Antioquia, we currently have two databases, (1) PC-GITA [Orozco 2015] which contains recordings of 100 speakers, 50 with PD and 50 age- and gender-matched healthy controls, and (2) ongoing data collection with recordings of speech, gait, and handwriting of currently 30 patients with PD.
For both databases we have demographics, MDS-UPDRS-III, and Hoehn&Yahr measures. By the time of the workshop the second collection will include all-day recordings with dynamics given medicine intake and professional evaluation of speech with the standardized Frenchay assessment. Finally, the Ontario Neurodegenerative Disease Research Initiative (ONDRI) provides a full battery of assessments, including speech, depression scores, and neuroimaging for 150 people with AD and 150 with PD. MIT is also providing 200 elderly audio/cognitive assessments as part of Thomas Quatieri’s research into MCI; this will continue in collaboration with the MIT Brain and Cognitive Science Department, McLean Hospital, and MGH.
Since assessment should be automated fully, our group is already adapting automatic speech recognition (ASR) tools for this task. Specifically, we have adapted models in Kaldi using maximum likelihood linear regression to older voices both with and without dementia, and are currently exploring the relationships between ASR and assessment accuracies. We are also using the ASR system in IBM Watson as part of Frank Rudzicz’s involvement in IBM’s Academic Initiative, and a deeper collaboration through AGE-WELL. We are naturally interested in working with other large commercial ASR systems.
Research Questions
 We have three research questions for the workshop:
We have three research questions for the workshop:
- Using ONDRI, do features cluster within pathological groups? We will continue to use factor analyses, but will add mixture-density networks and k-means clustering, using optionally a mixture of experts modeling, as baselines.
- Using Talk2Me, what effect does data recorded in the home vs. in the lab have on the machine learning for diagnostics? We will use static classifiers here, namely deep-belief networks and SVMs, and compare their performance using ANOVA.
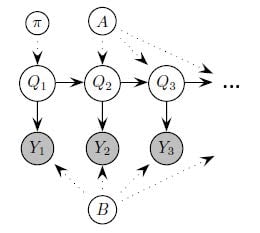
- Using DementiaBank, Talk2Me, ONDRI, and Antioquia, how do we most accurately model the dynamics of speech and, where available, biometric signals? Here, we will use dynamic Bayes networks (shown here), as we did in recent work (Yancheva and Rudzicz, 2015) and recurrent neural networks. It is possible we will use trajectory networks using mixture-density networks, and supra-segmental parametric speech representations (i.e. KL-HMM) to encode the dynamics.
- The follow up question is: What is the effect of high-frequency vs low-frequency assessment? This will follow using the same dynamical models as above.
Timeline
Before:
- Integrate all data and tools in CloudCAST,
- Prepare preprocessing scripts, ASR adaptation and code, other tools, and
- Prepare statistical frameworks for research goals, using existing code.
During:
- Find the most informative features across multiple modalities,
- Discover confounds (e.g., depression) with factor analysis, and
- Answer questions 1-3, listed above. In all cases, the accuracy of diagnosis is the primary objective function we will optimize.
After:
- Open a new collaborative continuous monitoring project. This will involve all members, including new partners involved in the summer school. We will seek project funding from sources such as NIH and NSF, and
- Work will later focus on applying the results into knowledge transfer. Several members of the team are already working towards this goal.
| Team Members | |
|---|---|
| Team Leader | |
| Elmar Noeth | University of Erlangen (Germany) |
| Senior Members | |
| Frank Rudzicz | Toronto Rehabilitation Institute (Canada) |
| Heidi Christensen | University of Sheffield (UK) |
| Juan Rafael Orozco-Arroyave | University of Antioquia (Colombia) |
| Hamidreza Chinaei | University of Toronto |
| Graduate Students | |
| Juan Camilo Vasquez-Correa | University of Antioquia (Colombia) |
| Maria Yancheva | University of Toronto (Canada) |
| Phani Shankar Nidadavolu | Johns Hopkins University |
| Julius Hannink | University of Erlangen (Germany) |
| Undergraduate Students | |
| Alyssa Vann | Stanford University |
| Nikolai Vogler | University of California-Irvine |
| Senior Affiliates (Part-time Members) | |
| Tobias Bocklet | University of Erlangen (Germany) |