Detecting Risk and Protective Factors of Mental Health using Social Media Linked with Electronic Health Records
- Research Group of the 2016 Third Frederick Jelinek Memorial Summer Workshop
- Team Presentations and Publications

Introduction
We propose a workshop centered around the first-of-its-kind “Penn SoMe+EHR Bank” [18], consisting of the electronic health records (EHR) and social media (SoMe) posts of thousands of consenting ER patients in the Philadelphia health system. We will focus on longitudinal analysis of social media to understand how the language and online behavior reflects the patients’ mental health diagnoses and medications (from the EHR). Our goals are to automatically detect crisis points in a patient’s lifeline, to discover features indicative of onset and recovery of mental health disorders, and to test the validity of prior research using social media for mental health – in particular, anxiety, eating disorders, drug abuse, and suicidal ideation.
Mental health is a global issue, and one where bringing technology to bear could have a real impact. Global mental health expenditure is estimated at $3.5 trillion [2]. Every year, 19% of Americans experience mental illness [27] and an estimated 4% have thoughts of suicide [1]. Traditional mental health data gives practitioners and scientists little insight into the everyday thoughts, feelings, and behaviors of patients (i.e., personalized health). Social media, now used regularly by over a billion people worldwide, gives us an unprecedented record of people’s daily lives in the form of Facebook status updates, Tweets, or Instagram messages. These unprompted “big data” are recorded in the moment and subject to different biases than traditional survey or laboratory data, thus opening the door for data-driven discovery of previously inaccessible, everyday factors and personalized interventions in mental health.
The strength of such data is reflected in the recent explosion of work using social media to detect and characterize individuals with mental health disorders [4, 5, 6, 9, 12, 13, 17, 25, 26]. The patterns found in these analyses are quite face valid (e.g., see Figures 1 and 2), corroborating the clinical literature. However, despite this large upswing in interest to tackle mental health through social media, there have been no studies linking social media language patterns with substantial clinical data – data to support such studies was lacking until the Penn SoMe+EHR Bank.
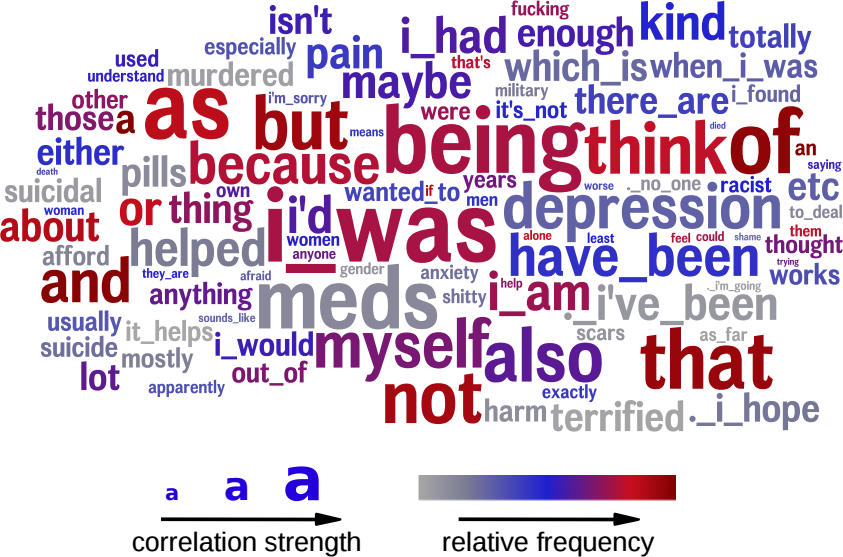 Figure 1: Words and phrases most predictive of self-reported diagnosis of PTSD on Twitter (as compared to age- and gender-matched control users). The color indexes relative frequency, from grey (rarely used) through blue (moderately used) to red (frequently used). |
 Figure 2: Topics (clusters of semantically-related words) most predictive of self-reported diagnosis of depression on Twitter (as compared to age- and gender-matched control users). Size indicates prevalence of word within topic. |
Research Questions
The proposed research aims specifically to address the following questions:
- Can we forecast mental health onset and recovery, as signaled in clinical records, based on social media features?
- What are the signals from everyday life, as manifest in social media language, that precipitate a shift in mental health?
- How do prescribed medicines affect the signals emanating from everyday life, and do changes in the language in social media correlate to the known side effects of medications?
Approach
We propose exploratory and predictive analyses of the joint temporal, linguistic, and medical information made available by the Penn SoMe+EHR Bank. We seek quantifiable and insightful signals related to mental health. We propose to focus on four mental health conditions: anxiety, eating disorders, drug abuse, and suicidality. These four conditions are quite prevalent with stated progression and relapse yet have previously been largely neglected in social media–based studies.
The proposed approach will begin with basic analysis of linguistic characteristics of the entries in a user’s timeline (i.e., Facebook status update, tweet, or Instagram post) coupled with the user’s linked diagnoses and/or prescribed medication information. The linguistic analysis will include basic natural language processing techniques previously demonstrated to have relevance to mental health, including language models, topic models, and sentiment analysis [5, 6, 15, 26]. One of the challenges this approach will have to face is that traditional techniques in NLP, designed to model documents or language itself, have limitations when modeling the people behind the language: variable encodings may not be appropriate [11], distributions may change, and predictive models are not always interpretable for person-level insights [19, 24]. As needed, deeper semantic representations and deep learning techniques will be employed.
Key to our study will be the use of time series analysis of the user’s social media timeline – including features beyond the language content, to include metadata such as the time and frequency of posting. We have repeatedly found when examining language related to mental health that there is significant information encoded in time, and so explicit joint and conditional analysis of linguistic and temporal information may yield new insight into mental health processes. Mental health symptoms and medication effects ebb and flow with time [21] and at many granularities (hourly, daily, weekly and seasonally) [8, 16, 23], but these clinically relevant signals are not readily accessible by traditional approaches to mental health. The Zipfian nature of language which yields very sparse terms and phrases makes common approaches to time series analysis [3, 10] non-trivial; we will explore Bayesian change point models [22] as well as forecasting models (such as ARIMA) [20]. Interestingly, temporal-linguistic structure is prevalent in a number of applied NLP domains, so progress here may yield gains beyond mental health as well.
Finally, we will conduct exploratory analysis of the highly-predictive, temporally-sensitive linguistic and metadata features to discover potential risk and protective factors for mental health. It will certainly be the case that the variables required to present a full picture of an individual’s changing mental health status will not all be present in the data, and so the models must be able to account for latent variables as well as the observables. Additionally, while clinical data is often looked to as some “gold standard” for the health of a patient, it does have a significant amount of error and noise. Clinical agreement on diagnoses related to mental health is particularly challenging at κ < 0.6 [14]. This means that the labeled diagnoses are not perfectly reliable, and techniques for supervised learning from noisy labels must be incorporated. Care will be taken to avoid discovery of spurious relationships by leveraging the size of our data to correct for the multiple hypotheses tested during exploratory analyses.
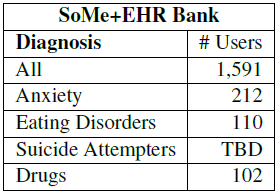 Figure 3: Size of SoMe+EHR Bank as of November 2015; expected to increase approximately 166% by June 2016. The mean number of status updates per user is 834. |
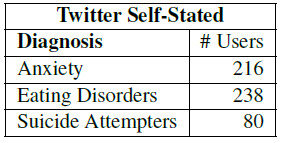 Figure 4: Number of Twitter users and their tweets from 2009-2015 with self-stated diagnoses of the listed conditions. The mean number of tweets per user is 3,084. |
Throughout the workshop we will be in regular discussion with our clinical panel and subject matter experts (see Team, below) to ensure that the analyses are reasonable, interpretable, and – hopefully – have the potential to effect real change in the field of mental health.
Data and Feasibility
Data connecting linguistic signals to markers of mental illness, diagnoses, or outcomes, has been traditionally difficult to find. The Penn SoMe+EHR Bank links status updates, going back 5 years, with participant medical records in the University of Pennsylvania Health System, which go back a decade. Table 3 shows the size of data sets we will work with in the workshop [18], while Table 4 shows the size of supporting Twitter data from previously published work [6, 8].
Despite the numerous challenges presented by our data and proposed approach, we also have reason to believe that achieving our stated goals will be feasible. Figure 5 demonstrates the accuracy with which our previous work [7] is able to model ten mental health conditions based on language modeling alone. Figure 6 demonstrates that change in language can be modeled over time, at an individual-level basis. Lastly, preliminary results within the SoMe+EHR Bank indicate that a diagnosis of anxiety can be predicted by one’s social media topics better than a model combining key demographic variables (age, gender, and race).
![Figure 5: ROC curves for distinguishing diagnosed from control users, for ten disorders as examined in [15], with anxiety and eating disorders highlighted as two of the proposed conditions of study for this workshop. Chance performance is indicated by the black diagonal line.](https://www.clsp.jhu.edu/wp-content/uploads/2016/03/SchwartzFig5.jpg) Figure 5: ROC curves for distinguishing diagnosed from control users, for ten disorders as examined in [15], with anxiety and eating disorders highlighted as two of the proposed conditions of study for this workshop. Chance performance is indicated by the black diagonal line. |
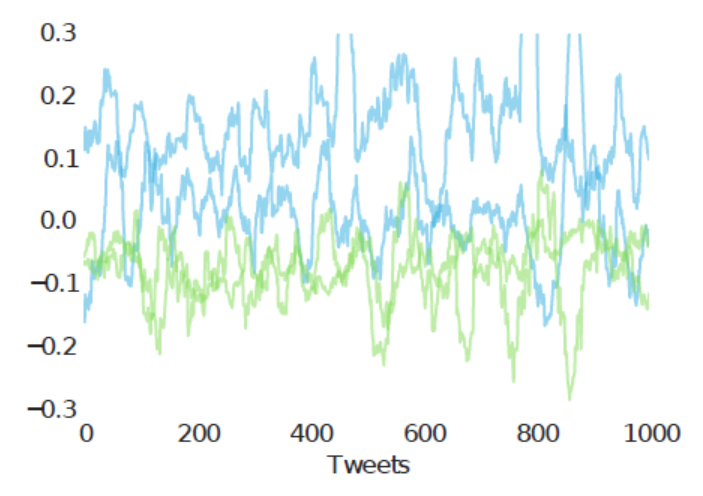 Figure 6: Timeline of the social media (Twitter) posts of 4 users—two users who attempted suicide (blue) and their age- and gender-matched controls (green)—scored by a character-based language model trained on the language of Twitter users prior to a suicide attempt. |
Goals and Outcomes
The overarching goal of the proposed workshop is to develop a better understanding of how to track mental health and wellness over time, with direct comparisons to clinical measurements and outcomes. Additionally, we expect to lay the foundation for further research into the temporal components of long-term mental health conditions. Information at this granularity, scale, and with clinical validation has never before been available, but can be the seed for revolution in mental health, wellbeing, and the scientific understanding of our selves.
| Team Members | |
|---|---|
| Team Leader | |
| Kristy Hollingshead | Institute for Human and Machine Cognition |
| Senior Members | |
| H. Andrew Schwartz | Stony Brook University |
| Glen Coppersmith | Qntfy |
| Dirk Hovy | University of Copenhagen |
| Raina Merchant | University of Pennsylvania |
| Graduate Students | |
| Patrick Crutchley | University of Pennsylvania |
| Fatemeh Almodaresi | Stony Brook University |
| Adrian Benton | Johns Hopkins University |
| Jeff Craley | Johns Hopkins University |
| Undergraduate Students | |
| Amos Kim | University of Colorado Boluder |
| Bu Sun Kim | University of Colorado Boulder |
| Senior Affiliates (Part-time Members) | |
| Molly Ireland | TexTech |
| Masoud Rohizadeh | Stony Brook University |
| Lyle Ungar | University of Pennsylvania |
| Meg Mitchell | Microsoft Research |
| Andreas Andreou | Johns Hopkins University |