Building Speech Recognition System from Untranscribed Data
- Research Group of the 2016 Third Frederick Jelinek Memorial Summer Workshop
- Team Presentations and Publications

Introduction
Modern automatic speech recognition (ASR) systems consist of two major statistical models: the Language Model (LM) and the Acoustic Model (AM). The LM models probabilities of word sequences and the AM describes distributions of acoustic features for individual phones (or senones). Typically, the two statistical models are independently trained from large volumes of text data and annotated speech data, respectively. The component connecting these two models is the pronunciation lexicon mapping words into phone sequences. The pronunciation lexicon is typically manually designed by an expert familiar with the language of interest. Recently, there has been an increased interest (e.g. in IARPA Babel and DARPA LORELEI programs) in rapidly developing ASR systems for new “exotic” low-resource languages, where such expert-level linguistic input and manual speech transcription are too expensive, too time consuming, or simply impossible to obtain.
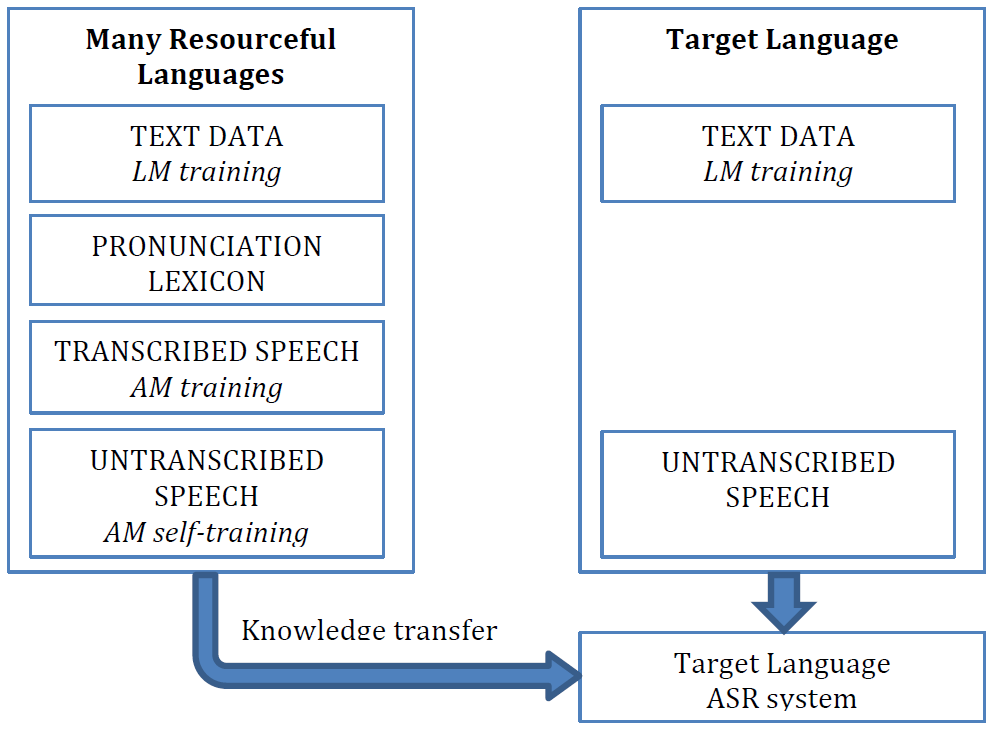
Figure 1
As illustrated in Figure 1, we propose to develop models and techniques that will allow us to train an ASR system for a new low-resource target language, where only text data and “unrelated” untranscribed speech recordings are available. During the training, the proposed models must be able to reveal and match the patterns seen in text data (i.e. the regularities seen in the word sequences) with similar patterns observed in speech signal. To accomplish this task reliably, we propose to leverage data from other high-resource languages, for which transcribed data and expert knowledge are available. For example, to discover patterns of phone-like units in speech, it is important to discriminate between the phonetic variability in the speech signal and the variability attributed to other causes (speaker, channel, noise, etc.). To a large extent, this knowledge can be learned from the transcribed speech of the high-resource languages and used for building the target ASR system.
Research
Recently, discriminatively trained Deep Neural Networks (DNNs) have very successful in ASR and have largely superseded the more traditional generative models. We also plan to use DNNs to facilitate knowledge transfer from the high-resource languages as will be described later. However, this project mainly focuses on Bayesian generative models, which are more suitable for the unsupervised discovery of latent patterns in untranscribed data. As illustrated in Figure 2, the envisioned generative model consists of the same components as the traditional model for ASR. A sequence of words is assumed to be generated from a “known” statistical language model, which can be estimated from the available text data. The word (or corresponding letter) sequence is converted into a sequence of acoustic (phone-like) units using the lexicon model. Finally, the corresponding sequence of observed speech features is assumed to be generated from the acoustic model. However, unlike in the case of the traditional ASR system with a handcrafted lexicon and supervised acoustic model training, a proper Bayesian non-parametric model will be used to represent the lexicon and acoustic model in order to jointly solve the following problems arising during the unsupervised training: 1) dividing speech into phone-like segments, 2) clustering the segments to obtain a repository of acoustic phone-like units, 3) learning the corresponding acoustic model (i.e. acoustic unit feature distributions), 4) learning the lexicon as a statistical model for translating letter sequence into a sequence of the discovered (possibly context-dependent) acoustic units, and 5) discovering sequences of acoustic units and words that are in agreement with the language model.
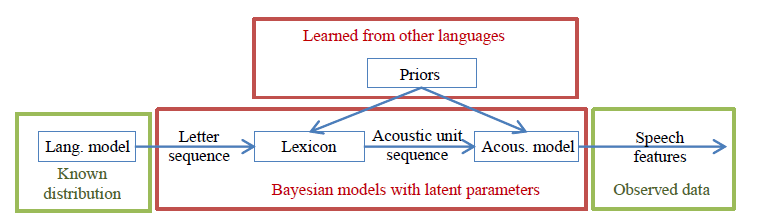
Figure 2
The important and novel feature of our model will be the possibility to learn from the high-resource languages. In the framework of Bayesian generative models, we can design a model where some of the parameters and latent variables are shared across languages. In other words, we can assume that speech from all languages is generated from a single properly defined generative model. Some of the variables can be considered as observed for the supervised languages and hidden for the target low-resource language. Posterior distributions over some latent variables estimated from the high-resource languages can be used as priors in the inference for the low-resource language.
Related Work
To give a more concrete idea of our envisioned model, we now review several previously proposed models, each focusing on some part of our problem. During the workshop, we would like to adapt these models to our needs and use them as the building blocks to solve the whole problem of training from untranscribed data. Note that the potential workshop participants are often the authors of the reviewed models or people with the appropriate expertise.
In (Lee, 2012), a Bayesian non-parametric model for acoustic unit discovery was proposed, based on a Dirichlet Process Mixture of HMMs. This model jointly solved the problem of 1) discovering acoustic units in speech signal, 2) segmenting speech into such units, and 3) learning their HMM models. In (Lee, 2013), the model was further extended with a pronunciation lexicon component based on Hierarchical Dirichlet distribution model. This model allowed the acoustic model to be trained from orthographically transcribed speech without any need for a handcrafted lexicon or definition of phonetic units by an expert. In these works, Gibbs sampling was used for inference, which made the training slow and impractical for application to larger data sets. Variational Bayesian inference is proposed to train a similar acoustic unit discovery model in (Ondel, 2015), where improvements in both scalability and quality of the discovered acoustic units were reported. None of the models, however, made any attempt to leverage the data from the high-resource languages to improve the acoustic unit discovery for the target language.
One simple way of using the data from the high-resource languages, which we also plan to investigate, is to use DNN based multilingual bottle-neck (BN) speech features for training the acoustic unit discovery model. The BN features, which are discriminatively trained on multiple languages to suppress information irrelevant for phone discrimination, have already proved to provide excellent performance when building ASR systems for languages with limited amount of transcribed data (Grézl, 2014).
The problem of acoustic unit discovery is very similar to speaker diarization. It was shown that a fully Bayesian model for speaker diarization can greatly benefit from Joint Factor Analysis inspired priors describing across-speaker variability in the space of speaker model parameters (Kenny 2010; Burget 2013). Similar priors describing within- and across-phone variabilities can be robustly trained from the high-resource languages and incorporated into our model for acoustic unit discovery. This concept is also similar to the Subspace GMM model, which was successfully used for multilingual acoustic modeling (Burget 2010).
Non-parametric Bayesian models based on Hierarchical Pitman-Yor Processes were successfully used to learn language models over word-like units automatically discovered (using the same model) in phone sequences or lattices (Neubig, 2012; Walter, 2013). These models, however, assume known acoustic units (phones), which can be obtained from continuous speech using an (error-free) phone recognizer. Heymann et al. extended this to a real (error-prone) phone recognizer and showed how, through alternating between language model learning and phone recognition, both improved phone error rates and improved word discovery F-scores could be obtained (Heymann, 2014).
Expected Outcomes
We expect to develop a framework for training ASR systems from untranscribed speech applicable to data sets of non-trivial size. Also, there will be no need for costly and time consuming construction of a pronunciation dictionary by an expert linguist. This framework should allow for a speech representation that is flexible enough to integrate knowledge from existing languages but also independent enough to discover new patterns in an unsupervised way. To achieve this goal, we will develop nontrivial extensions to the aforementioned models and combine them into a single functioning framework. Meta-heuristic optimization (Moriya, 2015) will be used to aid the search for the optimal model configuration and parameter settings.
The important part of our problem is the model for acoustic unit discovery, which will allow us to convert speech into discrete high-quality phone-like units. Beside the ASR task, this model might be also useful for a range of other speech applications, where reliable tokenization is requested (speaker recognition, language identification, query-by-example keyword spotting, etc). Therefore, we also plan to evaluate the quality of the discovered acoustic unit sequences by 1) their direct comparison with the true phone sequences (e.g. using the normalized cross-entropy measure), as well as 2) testing their performance in some of the mentioned speech applications.
As this is the first attempt to solve the whole problem of training ASR from untranscribed speech, we believe that the outcomes from the workshop will serve a starting point for new research in these directions. Different models and approaches providing much better performance will certainly emerge soon.
| Team Members | |
|---|---|
| Team Leader | |
| Lukas Burget | Brno University of Technology |
| Senior Members | |
| Takahiro Shinozaki | Tokyo Institute of Technology |
| Najim Dehak | Johns Hopkins University |
| Reinhold Haeb-Umbach | University of Paderborn |
| Daichi Mochihashi | Institute of Statistical Mathematics |
| Emmanuel Dupoux | École des Hautes Etudes en Sciences Sociales |
| Ming Sun | Amazon |
| Graduate Students | |
| Lucas Ondel | Brno University of Technology |
| Thomas Glarner | University of Paderborn |
| Mirko Hannemann | Brno University of Technology |
| Chunxi Liu | Johns Hopkins University |
| Matthew Wiesner | Johns Hopkins University |
| Santosh Kesiraju | International Institute of Information Technology |
| Ondrej Cifka | Charles University in Prague |
| Leda Sari | University of Illinois |
| Undergraduate Students | |
| Alena Rott | Stanford University |
| Yibo Yang | University of Texas at Dallas |
| Senior Affiliates (Part-time Members) | |
| Shinji Watanabe | Mitsubishi Electric Research Laboratory |
| Graham Neubig | Nara Institute of Science and Technology |