Structured Computational Network Architectures for Robust ASR
- Research Group of the 2015 Second Frederick Jelinek Memorial Summer Workshop
Despite the significant progress made in the past several years in automatic speech recognition (ASR), the ASR performance under low-SNR, reverberation, and multi-speaker conditions is still far from satisfactory, especially when the testing and training conditions do not match which is almost always the case in real world situations.
We perceive that, to solve the robustness problem, the desired system should have the following capabilities:
- Classification — because the goal of ASR is to classify the input audio signal to word sequences.
- Adaptation — so that the behavior of the system can automatically change under different (most likely mismatched) environments or conditions to achieve the best performance.
- Prediction — in order to provide information to guide the adaptation process and to reduce mismatch.
- Generation — so that the system not only can predict labels (e.g., speaker, phone) but also features and can focus on specific part of the signal, which is esp. important when there are overlapping speakers.
The behavior of prediction, adaptation, generation and classification is widely observed in human speech recognition (HSR). For example, listeners may guess what you will say next and wait to confirm their guess. They may adjust their listening effort by predicting the speaking rate and noise condition based on the current information, or predict and adjust the mapping from letter to sound based on the speaker’s current pronunciation. They may even predict what your next pronunciation would sound like and focus their attention to only the relevant part in the audio signal.
These capabilities are integrated in a single dynamic system in HSR. This dynamic system can be approximated at the functional level and described as a recurrent neural network (RNN) and implemented using the computational network toolkit (CNTK), which supports training and decoding of arbitrary RNNs.
A general simplified description of the model is:
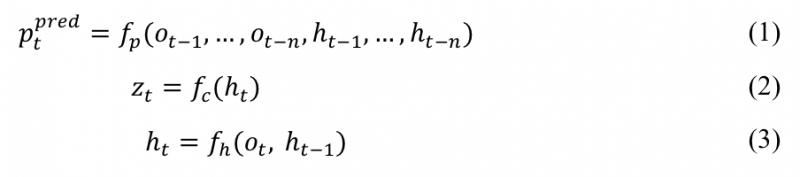
where ![]() are the noisy speech input, prediction result, hidden state, and output at time t, respectively, n is the window of frames the prediction is based on, and
are the noisy speech input, prediction result, hidden state, and output at time t, respectively, n is the window of frames the prediction is based on, and ![]() , and
, and ![]() are the nonlinear functions to make prediction and classification, and to estimate the hidden state, respectively. The predicted information can include, but not limited to, future phones, speaker code, noise code, device code, speaking rate, masks, and even the expected feature. The hidden state can carry over long short-term history information to the model.
are the nonlinear functions to make prediction and classification, and to estimate the hidden state, respectively. The predicted information can include, but not limited to, future phones, speaker code, noise code, device code, speaking rate, masks, and even the expected feature. The hidden state can carry over long short-term history information to the model.
The benefit of predicting and exploiting the auxiliary information can be shown using a simple example. Assume in the training time we learn ![]() where f is the function learned, y is the label, and x is the input feature. During the test time, x is corrupted and becomes
where f is the function learned, y is the label, and x is the input feature. During the test time, x is corrupted and becomes ![]() , where c is a constant channel distorsion. As a result
, where c is a constant channel distorsion. As a result ![]() , and we get degraded performance. However, if auxiliary information a, such as the noise level, channel distortion, and speaker id, is estimated and modeled during the training time, we get
, and we get degraded performance. However, if auxiliary information a, such as the noise level, channel distortion, and speaker id, is estimated and modeled during the training time, we get ![]() , where g is a function learned through training and we have put a structure into the model. During the test time the auxiliary information is estimated and the distortion of the feature can thus be compensated automatically as we have
, where g is a function learned through training and we have put a structure into the model. During the test time the auxiliary information is estimated and the distortion of the feature can thus be compensated automatically as we have ![]() .
.
Fig. 1 is a concrete example of such dynamic systems. The conventional ASR systems only contain the classification (right) component and thus cannot adapt to new environments. Slightly more advanced techniques estimate (often requires multiple passes of the utterances) some auxiliary information independently from the rest of the network and use it as the side-information to guide the adaptation. In our proposed approach shown in Fig. 1, the auxiliary information is predicted through an integrated prediction (left) component using past frames. The predicted auxiliary information helps to improve the classification component’s accuracy. The classification component’s processing result in turn helps to boost the performance of the prediction component. It is obvious that the classification component’s behavior adapts automatically based on the predicted information. At the same time, the prediction component’s behavior also adapts automatically based on the information fed back from the classification component.
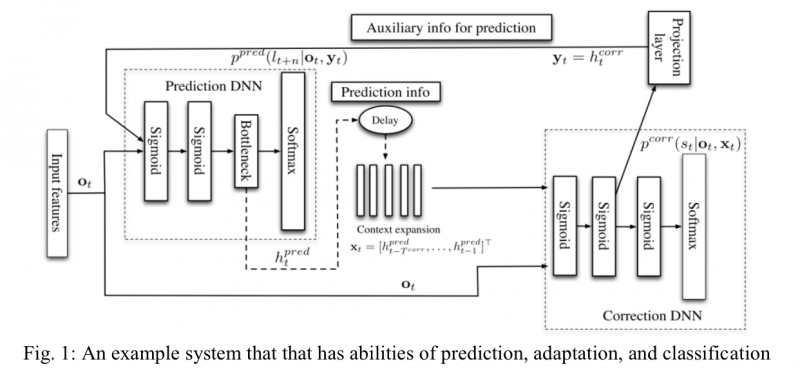 To train the model, we need labels for auxiliary information (many of which can be automatically generated) as well as the text transcription. The model will be trained to optimize multiple objectives (sometimes called multi-task learning), including both the final classification accuracy and the prediction accuracy.
To train the model, we need labels for auxiliary information (many of which can be automatically generated) as well as the text transcription. The model will be trained to optimize multiple objectives (sometimes called multi-task learning), including both the final classification accuracy and the prediction accuracy.
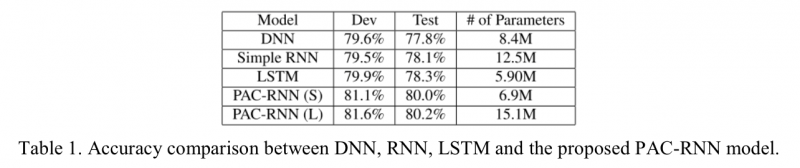
We have implemented and investigated a very preliminary version of the model, in which only the next phone is predicted and used as the auxiliary information and the predicted information is solely concatenated with the raw input feature, using CNTK and Argon decoder. Table 1. compares this preliminary model (PAC-RNN) with the state-of- the-art systems. From the table we can observe that the proposed approach is very promising.
To further advance the research along this line, we need to design computational network architectures that can predict other information such as speaker code, noise level, speech mask (to trace a specific speaker), and speaking rate. To exploit multiple auxiliary information we also need to develop more advanced structured adaptation techniques, in which the network’s parameters are jointly learned with different combination of factors and with the rest of the system. We will evaluate our model on the meeting transcription or Youtube (if data are available) task that features noisy far-field microphone, reverberation, and overlapping speech.
We expect to develop novel structured computational network architectures for robust speech recognition and shape a new research direction in attacking low-SNR, noisy and mismatched ASR. Besides the technology advancement, we will also contribute to the open source software. More specifically we will integrate Kaldi with CNTK so that Kaldi can have the ability to build arbitrary computational networks, including all existing architectures such as DNN, RNN, LSTM, and CNN as well as models we even don’t know today. This tool integration alone would help to move the field forward significantly.
| Team Members | |
|---|---|
| Team Leader | |
| Dong Yu | Microsoft Research |
| Senior Members | |
| Liang Lu | Edinburgh University |
| Khe Chai Sim | National University of Singapore |
| Graduate Students | |
| Souvik Kundu | National University of Singapore |
| Tian Tan | Shanghai Jiao Tong University |