Probabilistic Transcription of Languages with No Native-Language Transcribers
- Research Group of the 2015 Second Frederick Jelinek Memorial Summer Workshop
 Speech technology has the potential to provide database access, simultaneous translation, and text/voice messaging services to anybody, in any language, dramatically reducing linguistic barriers to economic success. To date, speech technology has failed to achieve its potential, because successful speech technology requires very large labeled corpora. Current methods require about 1000 hours of transcribed speech per language, transcribed at a cost of about 6000 hours of human labor; the human transcribers must be computer-literate, and they must be native speakers of the language being transcribed. In many languages, the idea of recruiting hundreds of computer-literate native speakers is impractical, sometimes even absurd. We propose to develop probabilistic transcription methods capable of generating speech training data in languages with no native-language transcribers. Specifically we propose a diversity coding scheme based on three transcription methods:
Speech technology has the potential to provide database access, simultaneous translation, and text/voice messaging services to anybody, in any language, dramatically reducing linguistic barriers to economic success. To date, speech technology has failed to achieve its potential, because successful speech technology requires very large labeled corpora. Current methods require about 1000 hours of transcribed speech per language, transcribed at a cost of about 6000 hours of human labor; the human transcribers must be computer-literate, and they must be native speakers of the language being transcribed. In many languages, the idea of recruiting hundreds of computer-literate native speakers is impractical, sometimes even absurd. We propose to develop probabilistic transcription methods capable of generating speech training data in languages with no native-language transcribers. Specifically we propose a diversity coding scheme based on three transcription methods:
(1) MISMATCHED ASR: Speech-to-text transcription using automatic speech recognition in pre-trained languages other than the one being transcribed, and using a global IPA phone set, is used to produce multiple parallel transcriptions.
(2) MISMATCHED CROWDSOURCING: Human crowd workers who don’t speak the target language are asked to transcribe it as if it were a sequence of nonsense syllables.
(3) EEG DISTRIBUTION CODING: Humans who do not speak the language of interest are asked to listen to its extracted syllables, and their EEG responses are interpreted as a probability mass function over possible IPA phonetic transcriptions of the speech.
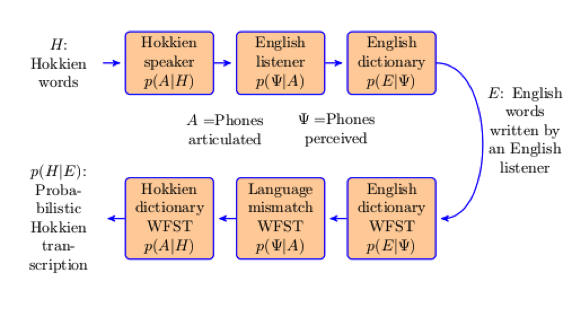 Mismatched crowdsourcing is the process of asking people who don’t speak a language to transcribe it, e.g., as a sequence of nonsense syllables. Mismatched crowdsourcing can be viewed as a kind of lossy communication channel: some of the information in the original signal has been systematically deleted by the untrained ears of the transcriber, but critically, some of the information is still available, even in the mismatched transcription. It is possible to estimate the channel substitution probabilities, and using the estimated probabilities, to find the most probable source message. Preliminary experiments demonstrate 96%-correct reconstruction of Hindi phoneme sequence based on nonsense syllable transcriptions by non-Hindi-speaking crowd workers.
Mismatched crowdsourcing is the process of asking people who don’t speak a language to transcribe it, e.g., as a sequence of nonsense syllables. Mismatched crowdsourcing can be viewed as a kind of lossy communication channel: some of the information in the original signal has been systematically deleted by the untrained ears of the transcriber, but critically, some of the information is still available, even in the mismatched transcription. It is possible to estimate the channel substitution probabilities, and using the estimated probabilities, to find the most probable source message. Preliminary experiments demonstrate 96%-correct reconstruction of Hindi phoneme sequence based on nonsense syllable transcriptions by non-Hindi-speaking crowd workers.
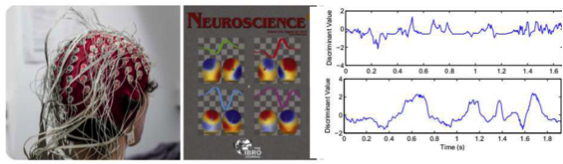 EEG distribution coding is a proposed new method that interprets the pre-categorical electrical evoked potentials of untrained listeners (measured by an electro-encephalograph or EEG) as a posterior probability distribution over the phone set of the foreign language. Transcribers, in this scenario, are speakers of English whose EEG responses to English speech have been previously recorded. From their responses to English speech, an English-language EEG phone recognizer is trained. In order to transcribe non-English speech, the speech is played to these listeners. The vector of posterior probabilities p(English phone|EEG) is computed, for all English phones, and is interpreted as an index into possible non-English phone strings; e.g., an ambiguous posterior probability vector is interpreted as evidence of a phone that does not exist in English.
EEG distribution coding is a proposed new method that interprets the pre-categorical electrical evoked potentials of untrained listeners (measured by an electro-encephalograph or EEG) as a posterior probability distribution over the phone set of the foreign language. Transcribers, in this scenario, are speakers of English whose EEG responses to English speech have been previously recorded. From their responses to English speech, an English-language EEG phone recognizer is trained. In order to transcribe non-English speech, the speech is played to these listeners. The vector of posterior probabilities p(English phone|EEG) is computed, for all English phones, and is interpreted as an index into possible non-English phone strings; e.g., an ambiguous posterior probability vector is interpreted as evidence of a phone that does not exist in English.
In the workshop we propose to use active learning to select the waveforms whose mismatched crowdsourcing and/or EEG distribution coding would be most informative. Specifically, Mismatched ASR (automatic speech recognition using phone recognizers in a variety of languages not including the language of the utterance) can be used to generate information about the possible target-language phonetic transcription of the utterance. Noisy channel methods, similar to those of mismatched crowdsourcing (Fig. 2), can be used to decode the target-language phone string. Two models trained for perfect recall (G: the “general model”) and perfect precision (S: the “specific model”) can be compared, and waveforms demonstrating the greatest S-G difference are retranscribed using mismatched crowdsourcing and/or EEG distribution coding.
Workshop deliverables:
(1) SOFTWARE: Extensions to OpenFST that permit estimation of foreign-language phone confusion probabilities that can be used, e.g., in a noisy channel model of mismatched crowdsourcing and/or mismatched ASR.
(2) ALGORITHMS: that transcribe Speech from EEG.
(3) SCIENCE: Expected significant scientific publications, e.g., first-ever study of EEG correlates of foreign-language phone classification.
(4) MODELS: Transcribed speech and trained audio speech-to-text in 70 languages. Currently we plan to use the 70 languages whose podcasts are published by the Special Broadcasting Service of Australia; among those 70, we believe that transcribed speech and trained speech-to-text models do not currently exist in Armenian, Assyrian, Bangla, Bosnian, Bulgarian, Burmese, Croatian, Dinka, Estonian, Fijian, Gujarati, Hmong, Hungarian, Kannada, Khmer, Kurdish, Lao, Latvian, Lithuanian, Macedonian, Malay, Malayalam, Maltese, Maori, Nepali, Punjabi, Samoan, Sinhalese, Slovak, Slovenian, Somali, Tigrinya, Tongan, or Ukrainian.
(5) EVALUATION METRICS: trained audio speech-to-text will be evaluated in one of two ways, depending on whether or not we have access to at least one native speaker of the language being evaluated. If a native speaker is available, that native speaker will be asked to transcribe a small test corpus, on which we will compute word error rate. If not, speech-to-text will be evaluated based on its training criteria, viz., likelihood of the audio given the phone string and/or entropy of the phone string given the audio.
| Team Members | |
|---|---|
| Team Leader | |
| Mark Hasegawa-Johnson | University of Illinois |
| Senior Members | |
| Preethi Jyothi | University of Illinois |
| Edmund Lalor | Trinity College, Dublin |
| Adrian KC Lee | University of Washington |
| Majid Mirbagheri | University of Washington |
| Graduate Students | |
| Amit Das | University of Illinois |
| Giovanni di Liberto | Trinity College, Dublin |
| Bradly Ekin | University of Washington |
| Hao Tang | Toyota Technological Institute |