CHANEL: Chat/Dialogue Modeling and Evaluation

2020 Seventh Frederick Jelinek Memorial Summer Workshop
We propose two activities to advance the state of the art in conversational systems: end-to-end training from speech to dialogue understanding, and automated evaluation of dialogue beyond metrics of task success. The first activity is intended to overcome the loss of information that stems from current pipelined approach, where training is split into speech recognition which produces text transcripts from the speech signal, and language understanding which is typically trained only on transcripts. The second activity is intended to enable automated testing for aspects that maintain relations and rapport in a conversation, as useful testing is a key factor in enabling automated learning. The two activities will be tied together with the development of shared data and a shared application: we will create a dialogue corpus that can be used both for end-to-end training and for the development of conversational evaluation metrics, and we will work towards an application that is trained in an end-to-end fashion using conversational metrics. The corpus and application will be shared with the community.
Background
Computer systems that interact with humans have existed for some time, both as subjects of research and as systems deployed commercially. Early systems we quite primitive but continued to evolve. At present they are pervasive in client-interaction applications; these are known as task or goal-oriented systems. In the research community interest has begun to focus on so-called conversational systems that can engage humans in non-taskoriented social interaction where the goals are different and not always obvious.
Natural language understanding (NLU) components are trained on transcripts while ASR is trained on audio. Further, each component is trained and optimized independently and with different objective criteria. As noted in [Serdyuk 2018] this independent training and optimization leads to components that do not treat the input audio in a unified way for the task at hand: detect the relevant features (e.g. domain, intents, slot values) in order to perform the task at hand. For example, transcribing all words accurately may not be necessary since not every word has the same importance/impact on intent classification or slot filling accuracy (see [Braunschweiler 2018], [Serdyuk 2018]). Another issue that NLU modules are typically trained on clean text without ASR errors and possibly on a limited number of utterance variations. In evaluation or production these systems use the ASR output and thus errors in transcription (especially due to noisy conditions or confusable words) can be propagated to NLU, degrading performance due to mismatched conditions between training and testing.
Recent success in end-to-end ASR related tasks ([Amodei 2016], [Chan 2016], [Soltau 2016], [Chorowski 2015], [Bahdanau 2016], [Chen 2016]) suggests that end-to-end training and optimization of a complete the whole system ASR-NLU system for SLU. Further inspiration comes from research [Tomashenko 2019] related to end-to-end speech-to-NLU. We will measure performance on the single-turn intent classification, named-entity recognition (NER) and slot filling accuracy, both individually and jointly, starting from log-Mel filterbank features directly.
Recently researchers have begun to investigate the integration of goal-oriented dialog systems and conversational systems (blending) and finding that these are both better accepted by users and appear to produce better task outcomes (e.g. [Zhao 2018, Shi 2020]). Blended systems can be evaluated objectively (e.g. success in negotiation) much as dialog systems have been in the past. But there is little agreement on the correct way to evaluate social conversation. The only widely accepted approach has been to ask human judges to rate conversation quality on a numeric scale, possibly augmented by questionnaires.
Judge-based evaluation is expensive (because of human involvement) and is not well-suited for systematic investigations. There is a great need for automated, objective evaluation. Related fields, such as automated speech recognition (ASR), began to make impressive progress once the right performance metrics became established. The goal of this workshop is to develop metrics that will serve the same purpose for conversation (‘conversational’ AI as a discipline and ‘agents’ as artifacts). Nevertheless, all components from such a system, from speech-in to speech-out, play a role in performance and continue to be studied.
Chat evaluation presents a set of unique problems that are not present in goal-directed dialog systems [Deriu 2019]. For example, chat typically does not have a specific goal whose success or failure can be used to build performance metrics. Techniques have been proposed (e.g. [Walker 1997], [Walker 2001]) for goal directed systems. Key metrics were identified that, in addition to user satisfaction, could provide objective measures of performance; these included task time, number of turns, error rates at word, sentence and concept levels, and task completion. Such metrics, except for satisfaction, are not directly applicable to chat. For example, desirable properties of goal-directed dialog, such as brevity, are in fact considered undesirable in chat. Current chat metrics focus on difficult to quantify properties such as coherence and engagement. For this reason, evaluation of chat relies primarily on human judgement, even as automated methods continue to be investigated [Liu 2016], [Lowe 2016], [Lowe 2017]. In CHAVAL we are specifically interested in systems that are conversational; we believe that conversational skill is an identifiable component of language-based communication and that it needs to be studied as such.
Chat systems can be implemented using either spoken language [Aggarwal 2012] or text interfaces, with the latter currently more common. The WOCHAT initiative collected and annotated chat data [D’Haro 2016] as part of an evaluation exercise [Cercas 2016] meant to support research in automated annotation. Similarly, the Dialogue Breakdown Detection Challenge [Higashinaka 2017] has also explored automated annotation of chat at the turn level. In addition, the Conversational Intelligence Challenge (ConvAI) has collected a fair amount of data [Logacheva 2018]. The Alexa Prize competition [Ram 2018] has collected a significant conversation corpus and has annotated a substantial portion. In most of the cases, human evaluations are conducted to assess the quality of the dialogues. Subjective evaluation is likely to a role, but we believe that progress, particularly for learningbased approaches (e.g. [Yu 2016]) will require objective metrics. More recently ChatEval [Sedoc 2019] offers a framework for implementing automatic evaluations.
During this workshop we propose to investigate objective metrics for evaluating conversation, both on the global level (as discussed above) and on a turn-by-turn level, the latter addressing the need to understand factors that lead to “correct’’ performance. Such metrics can provide real-time performance monitoring of running systems, information that can be used to manage agent behavior and give better outcomes.
The NLU component will be integrated into a full conversational system (i.e. the platform being used for conversation) with goal of understanding how the conversational metrics discussed above can inform automatic training of NLU and ASR components. The integrated system (with the NLU outputting intents and slots compatible with the conversational agent). The automatic conversation metrics can then flow back into the ASR/NLU and be used for training; essentially providing a loss function for training.
We believe this will create the framework for truly end-to-end conversational system training that can be used for real-world applications, augmenting other approaches [Liu 2019].
Approach
Our plan is ambitious, but we believe that significant progress will be made on creating a framework that allows the implementation of realistic end-to-end conversation systems.
We have already identified several corpora that can be used for preliminary exploration of automated approaches to evaluating conversational agents. These include such existing datasets (ATIS: 5409 utterances; MultiWoz: https://arxiv.org/abs/1810.00278, Maluba: 5899 utterances; WOCHAT: 20000 turns available, Twins Corpus: 60000 turns), These will prepared and annotated with respect to characteristics of interest (e.g. breakdown, user satisfaction, etc.) However each of these corpora have shortcomings, e.g. they might be a narrow domain-specific task, or may not have the original speech available. Others are text-based so no speech exists.
Thus a critical goal for the workshop is to define a task and system that can be used to collect end-to-end data. There are several candidates. For example existing Alexa Prize systems, one of which has been deployed by a workshop participant. We have additional candidates under consideration, for example a question-asking system. We expect to implement and deploy the target system in the Amazon Alexa environment, with an arrangement to capture the speech data (either by fielding our own front-end or through a yet-to-be negotiated arrangement with Amazon). The question-answering system above uses such a configuration, which, in turn, does not present a major implementation challenge. We expect this work to be in progress before the start of the workshop. This will also provide an opportunity to establish baseline performance and determine whether instrumentation is as required.
Spoken language understanding baselines: will include performance on transcribed data for intent classification, NER, and Slot Filling. Response generation baselines, include both generative and retrieval based systems pre-trained with our curated corpus. We will explore different architectures for individually training Speech to NER, Speech to Intent, and Speech to Slot Filling components, as well as jointly trained Speech to NER-Intent-Slot Filling. This work will be conducted during the workshop.
In order to evaluate the conversational component, we will ensemble methods to automatically predict humangenerated evaluations and compare conversational agent implementations combining different spoken language understanding and response generation systems. Special attention will be paid to the incorporation of confidence information provided by the spoken language understanding into the overall evaluation score, as well as the potential use of the latter as a training signal of the overall system. This work will be conducted during the workshop.
The workshop will produce resources that will be of use to other researchers in the field, including the instrumented systems used for data collection and evaluation. All data (including speech, transcriptions NLU outputs, acoustic features used in conversation evaluation, and system logging information).
All collected and annotated data, developed systems and conducted experiments will be properly archived and documented aiming at providing a research resource that can be freely distributed and used after the workshop. We will organize the measuring instruments we develop so that also can be of use to others.
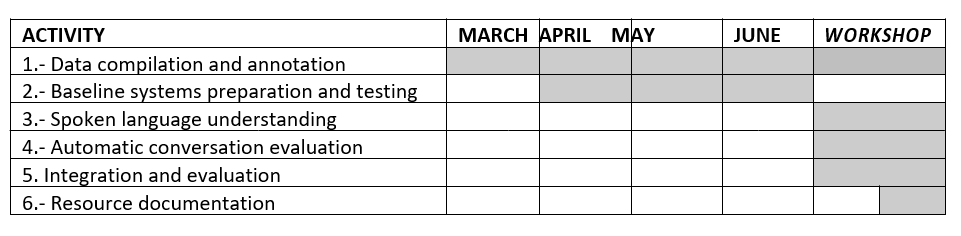
Timeline
The chart below shows our work plan in the period up to and including the workshop:
Potential risks and mitigation plan
The workshop has ambitious goals and it we should be cautious in assuming these will be achieved completely. The main risk, from our current perspective, is the ability to collect the data that will be necessary for the workshop. To recap this needs to be a substantial corpus coming from a well instrumented system that includes as key data (speech, transcription, understanding, conversation flow and outcomes as judges by users and by independent judge). This represents a significant effort and time commitment. The result will, however, be of great value both for the workshop and for other researcher.
The ASR/NLU work will take time to reach its goals, so integration will take place towards the end of the workshop. For conversation we intend to use off-the-shelf ASR and domain-specific NLU that we will need to build. This will support the metrics work.
We anticipate other challenges will appear but we are confident that we will be able to adapt.