Continuous Wide-Band Machine Translation
- Research Group of the 2015 Second Frederick Jelinek Memorial Summer Workshop
Continuous space models of language (CSMs), have recently been shown to be highly successful in text processing, computer vision and speech processing. CSMs are compelling for machine translation since they permit a diverse variety of contextual information to be considered when making decisions about local (e.g., lexical and morphological) and global (e.g., sentence structure) translation decisions. They thus promise to make machine translation more practical with fewer examples of parallel sentences by leveraging limited parallel data more effectively. Beyond this their flexibility allows for learning representations from other data sources such as monolingual corpora (thus, improving performance in low-resource settings), as well as allowing for translation decisions to be more easily conditioned on context (thus, improving the state-of-the-art in high-resource scenarios). At a high level, our workshop has the following goals: (i) develop a suite of tools to make experimentation with continuous space translation models practical; (ii) demonstrate their effectiveness in low-resource translation scenarios; and (iii) develop models that condition on non-local context– in particular discourse structure– to improve the state of the art in high-resource scenarios.
Scientifically, our modeling efforts will focus on what we call wide-band translation, reflecting the fact that translation decisions can be modeled locally (at the word and phrase level), at the sentence level, and at the discourse level. Current models for translation emphasize sentence-level models, relying on heuristically learned word- and phrase-level models, and ignoring the document context entirely. While it is reasonable to assume that a document translation that consists of good sentence translations will generally be effective, wide-band translation suggests that each level should be modeled independently and then merged into a single global model. This approach enables the translation problem to be decomposed into subproblems that can be addressed independently, using customized resources and models. Additionally, by controlling the number of outputs generated by the local model, the computational complexity of performing inference in subsequent models can be carefully controlled to balance translation quality and decoding speed. We discuss the research focus of each of these levels in turn.
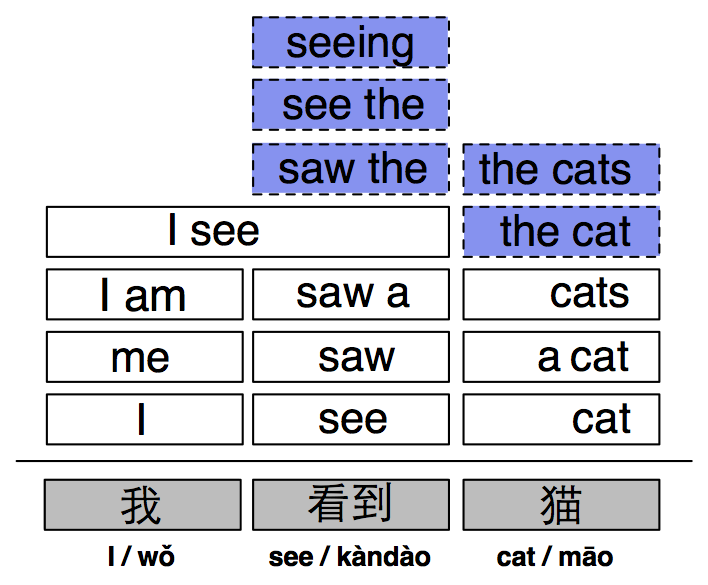 Local translation modeling. Local translation modeling refers to making decisions about the likely translation possibilities for words and phrases in the input– in the context of the document and sentence they occur in. These are then pieced together by subsequent models to build complete translations. In current statistical translation models, the likely translation options that are available for each word or phrase are limited by the translations observed in a parallel corpus where the available translations for some input must exactly match observed words and phrases in the parallel training data. Local translation modeling seeks to extend the inventory of phrases available to later models by synthesizing translation options that would not be available to the sentence-level model in a traditional approach– when such local translations are missing, building a translation is like putting together a puzzle with missing pieces. To illustrate how this can go wrong, in the figure to the right, the translation options necessary to generate the plausible translation I saw the cats are missing. Our modeling efforts here will construct word and phrasal translations by modeling morphological processes (enabling us to model translations with units generally much smaller than can be effectively used in sentence- level translation models), modeling the dependence of translation decisions based on the syntactic and discursive contexts they occur in, and generating lexical translation options from word embeddings learned from monolingual corpora (thus minimizing the amount of parallel data necessary to perform translation). Sentential translation modeling. Equipped with an inventory of translation options for subspans of the input, the task of generating a sentence translation is putting these pieces together in a sensible order. This is a deceptively complex problem: modeling how to reorder phrasal units into an appropriate order requires modeling interactions between the local decisions, formulating a distribution over word/phrase permutations, and searching this space. Dynamic programming search algorithms from context-free parsing enable a large subset (expotnential in the length) of the permutation space to be searched in polynomial time; however, modeling this space are notoriously difficult since the relevant features for determining word order are not obvious.
Local translation modeling. Local translation modeling refers to making decisions about the likely translation possibilities for words and phrases in the input– in the context of the document and sentence they occur in. These are then pieced together by subsequent models to build complete translations. In current statistical translation models, the likely translation options that are available for each word or phrase are limited by the translations observed in a parallel corpus where the available translations for some input must exactly match observed words and phrases in the parallel training data. Local translation modeling seeks to extend the inventory of phrases available to later models by synthesizing translation options that would not be available to the sentence-level model in a traditional approach– when such local translations are missing, building a translation is like putting together a puzzle with missing pieces. To illustrate how this can go wrong, in the figure to the right, the translation options necessary to generate the plausible translation I saw the cats are missing. Our modeling efforts here will construct word and phrasal translations by modeling morphological processes (enabling us to model translations with units generally much smaller than can be effectively used in sentence- level translation models), modeling the dependence of translation decisions based on the syntactic and discursive contexts they occur in, and generating lexical translation options from word embeddings learned from monolingual corpora (thus minimizing the amount of parallel data necessary to perform translation). Sentential translation modeling. Equipped with an inventory of translation options for subspans of the input, the task of generating a sentence translation is putting these pieces together in a sensible order. This is a deceptively complex problem: modeling how to reorder phrasal units into an appropriate order requires modeling interactions between the local decisions, formulating a distribution over word/phrase permutations, and searching this space. Dynamic programming search algorithms from context-free parsing enable a large subset (expotnential in the length) of the permutation space to be searched in polynomial time; however, modeling this space are notoriously difficult since the relevant features for determining word order are not obvious. 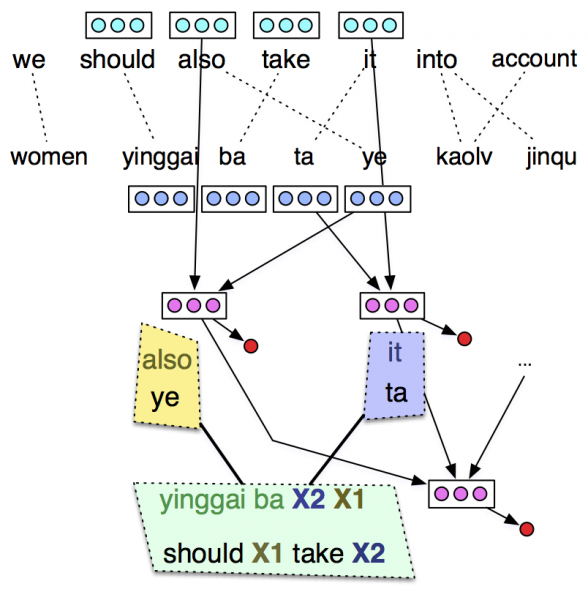 Our insight here is to exploit the fact that when local translation decisions are combined their meanings should compose to form a semantically coherent whole. We will operationalize this using compositional models of vector semantics that have been proposed in previous work for monolingual applications, where each decision about reordering (or, in the context of grammar-based models where reordering is driven by nonterminal substitution) is determined by using the composed vector representation to predict the appropriateness of the composed unit in a translation. See the figure to the left. Thus, this reduces the reordering problem to a series of nested binary classification decisions which can be trained using parallel data. Since the vector size of the constituents and composed representations are specified, statistical efficiency can be maintained, even in low-resource scenarios.
Our insight here is to exploit the fact that when local translation decisions are combined their meanings should compose to form a semantically coherent whole. We will operationalize this using compositional models of vector semantics that have been proposed in previous work for monolingual applications, where each decision about reordering (or, in the context of grammar-based models where reordering is driven by nonterminal substitution) is determined by using the composed vector representation to predict the appropriateness of the composed unit in a translation. See the figure to the left. Thus, this reduces the reordering problem to a series of nested binary classification decisions which can be trained using parallel data. Since the vector size of the constituents and composed representations are specified, statistical efficiency can be maintained, even in low-resource scenarios.
A second challenge related to global sentence modeling that will be addressed in modeling sentences with continuous space variables will be decoding. The standard dynamic programming approaches that are taken in the literature will be rendered ineffective since recombination will no longer be possible. For these models our starting point will be a reranking framework, but during the course of the workshop, more efficient decoding algorithms will be developed. Beyond their application to identify the best translation, an efficient decoding algorithm will facilitate the development of alternative training objective functions; part of the workshop efforts will look at various options, including local cross-entropy training, global margin maximisation, and data reconstruction error using auto-encoders. We anticipate that the choice of training objective will be important for learning in situations where there is considerable derivational ambiguity, as occurs with modern state of the art phrase-based and grammar based decoders in high resource translation settings.
Discourse translation modeling. Conventional approaches to machine translation translate sentences independently of one another and without reference to the discourse context they occur in. This is a serious limitation. For example, in languages with relatively free word order, information status of syntactic constituents tends to determine where they should appear. 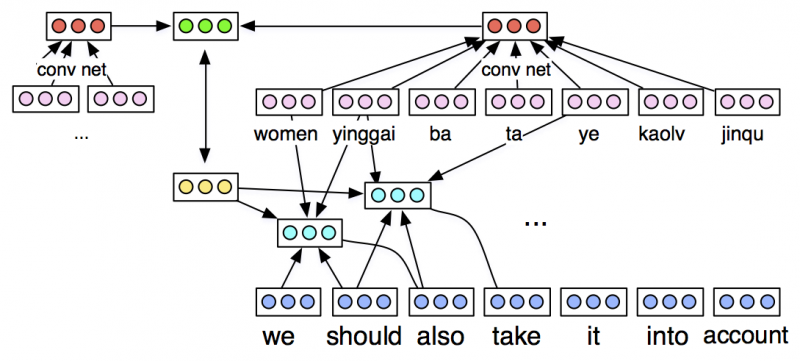 Thus, our final scientific contribution will be to explore the incorporation of discourse context in translation modeling. A serious challenge in modeling discourse dependency is determining what the relevant representation of discursive context is: while lexical and syntactic features can be effectively captured with hand-engineered features accessible via standard NLP tools, linguistic theory offers strongly divergent accounts of the appropriate representation of discourse. A key aspect of the workshop will be comparing different feature sets determined by different discourse parsing formalisms, as well as purely unsupervised acquisition of extra-sentential features via convolutional neural networks. Refer to the figure to the left for an illustration of a translation architecture that incorporates extra sentential information as a pair of vectors in the source and target languages.
Thus, our final scientific contribution will be to explore the incorporation of discourse context in translation modeling. A serious challenge in modeling discourse dependency is determining what the relevant representation of discursive context is: while lexical and syntactic features can be effectively captured with hand-engineered features accessible via standard NLP tools, linguistic theory offers strongly divergent accounts of the appropriate representation of discourse. A key aspect of the workshop will be comparing different feature sets determined by different discourse parsing formalisms, as well as purely unsupervised acquisition of extra-sentential features via convolutional neural networks. Refer to the figure to the left for an illustration of a translation architecture that incorporates extra sentential information as a pair of vectors in the source and target languages.
Languages and resources. We will target translation between English and three typologically representative languages: German, Czech, and Malagasy, an Austronesian language spoken by 18 million people, mostly in Madagascar. Czech and Malagasy word order is determined largely by information status of NPs, making them an ideal test case for our models. All three have rich morphological paradigms that mean that the naive lexical assumptions made in conventional translation are poorly suited. And Malagasy is representative of the small-resource scenario, where we must learn our models from limited parallel data. All three have standard parallel corpora and machine translation test sets available with standard baselines. Additionally, Czech has a discourse treebank enabling us to explicitly model discourse relations in a non-English source language. Finally, discourse analysis has been most widely studied in English, and Gatech’s state-of-the-art RST parser will be used in this workshop.
Why now? This is an optimal time to pursue the development of a suite of common tools for continuous space language models.Existing toolkits for machine translation (cdec, Moses) are in wide use, and generic tools for devel- oping training and inference algorithms with continuous space models are likewise available (Theano, CNTK, Caffe). From an engineering perspective, they need only be combined. In terms of research interest, there are numerous research groups around the world exploring continuous space models for translation, and this workshop will bring these groups together to avoid inefficient duplication of effort. This workshop is an opportunity to shape and spur future research in this area, and popularise the importance and academic challenges of low resource translation.
Expected impact. The expected impact of this workshop will be an open-source toolkit for training and decoding with continuous space language and translation models, a reference reimplementation of standard continuous space translation models, publications showing the effect of our wide-band translation formulation, specific topics in trans- lation modeling (at the local and sentential levels), a series of publications on the role of discourse in translation, and papers on low-resource translation using continuous space models with extremely limited parallel data resources.
| Team Members | |
|---|---|
| Team Leader | |
| Chris Dyer | Carnegie Mellon University |
| Senior Members | |
| Trevor Cohn | Melbourne University |
| Kevin Duh | Nara Institute of Science & Technology |
| Jacob Eisenstein | Georgia Institute of Technology |
| Kaisheng Yao | Microsoft Research |
| Graduate Students | |
| Yangfeng Ji | Georgia Institute of Technology |
| Austin Matthews | Carnegie Mellon University |
| Ekaterina Vylomova | Melbourne University |
| Bahman Yari Saeed Khanloo | Monash University |